一、先验知识
1、条件概率的一般形式
P(A,B,C)=P(C∣B,A)P(B,A)=P(C∣B,A)P(B∣A)P(A)
P(B,C∣A)=P(B∣A)P(C∣A,B)
证明:
左边:P(B,C∣A)=P(A,B,C)/P(A)
右边:P(B∣A)=P(A,B)/P(A); 而 P(C∣A,B)=P(A,B,C)/P(A,B); 两项相乘得:P(A,B,C)/P(A)
2、基于马尔可夫假设的条件概率
如果满足马尔可夫链关系A->B->C, 那么有
P(A,B,C)=P(C∣B,A)P(B,A)=P(C∣B)P(B∣A)P(A)P(B,C∣A)=P(B∣A)P(C∣B)
因为马尔可夫的性质就是当前时刻的状态只与前一时刻有关,即C只与B相关,B只与A相关
3、高斯分布的KL散度公式
对于两个单一变量的高斯分布p和q而言,它们的KL散度为
KL(p,q)=logσ1σ2+2σ22σ12+(μ1−μ2)2−21
4、重参数技巧 (很重要)
若希望从高斯分布 N(μ,σ2)中采样, 可以先从标准正态分布 N(0,1)采样出 ϵ,再通过σ∗ϵ+μ得到采样结果。这样做的好处的将随机性转移到了 ϵ这个常量上,而σ和μ则当作仿射变换网络的一部分。
二、Diffusion Model
如下图所示,扩散模型定义了一个马尔可夫链:
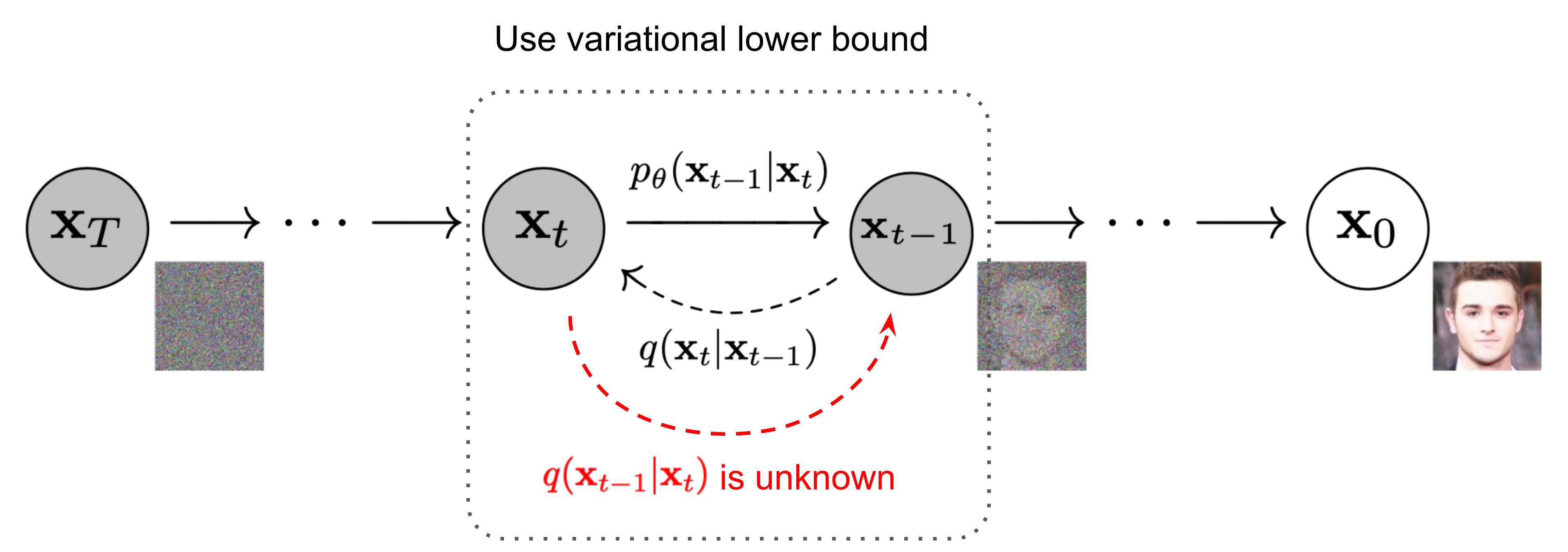
在扩散过程 (x0→xT) 中,慢慢地给原始图片(或者叫原始数据分布)添加高斯噪声,x0 表示从真实数据集中采样得到的一张图片,对x0 添加T次噪声,随着噪声的不断添加,图片逐渐变得模糊,当T足够大时,最终数据分布就变成了一个各项独立的高斯分布,即xT为标准正态分布。在训练过程中,每次添加的噪声是已知的,即q(xt∣xt−1)是已知的,根据马尔科夫链的性质,可以递归得到q(xt∣x0),即扩散过程是已知的。
我们需要学习的是逆扩散过程(xT→x0),从噪声中构建出原来的图片。假如我们能够在给定xt的条件下计算出xt−1,即知道q(xt−1∣xt),那我们就能够从任意一张噪声图片中经过一次次的采样得到一张图片而达成图片生成的目的。不幸的是我们很难估计q(xt−1∣xt),因为它需要用整个数据集来估计,所以我们希望能够用一个神经网络pθ(xt−1∣xt)来近似这个逆扩散过程q(xt−1∣xt)。
下面进行扩散过程与逆扩散过程的推导。
1、扩散过程
给定初始数据分布x0∼q(x), 我们定义一个马尔科夫链的前向扩散过程,该过程中的每个时间步t我们慢慢地向分布中添加高斯噪声,该噪声的标准差是由固定值βt确定,均值由βt和当前时刻的数据xt决定。βt定义为(0,1)的小数,即{βt∈(0,1)}t=1t,那么这个扩散过程可以记为
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
根据基于马尔可夫假设的条件概率公式,有
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
随着时间t逐渐增大,初始数据分布逐渐失去其具有判别性的特征;当T→∞,最终数据分布xT就等价于一个各向独立的高斯分布。
在扩散过程中,一般而言是一步一步迭代来算出每一步的噪声样本,即根据x0计算x1,根据x1计算x2,……,一直迭代直到xT。但是,实际上利用重参数技巧,我们完全可以基于x0和βt计算出任意时刻的xt,而不需要做迭代。
要求噪声样本xt,就得从分布N(1−βtxt−1,βtI)中抽样,根据重参数技巧,我们可以先从标准正态分布N(0,I)中采样出ϵt−1,然后根据重参数技巧得xt=1−βtxt−1+βtϵt−1,为简化公式,记αt=1−βt,则有
xt=αtxt−1+1−αtϵt−1; where ϵt−1∼N(0,I)
同理,
xt−1=αt−1xt−2+1−αt−1ϵt−2; where ϵt−2∼N(0,I)
把xt−1代入上式,则有
xt=αtαt−1xt−2+αt(1−αt−1)ϵt−2+1−αtϵt−1;
注意,两个正态分布x∼N(μ1,σ12)和Y∼N(μ2,σ22)叠加后的分布ax+bY的均值为μ=aμ1+bμ2,方差为σ2=a2σ12+b2σ22。由于ϵt−1和ϵt−2是标准正态分布,即N(0,I), 因此αt(1−αt−1)ϵt−2+1−αtϵt−1∼N(0,(1−αtαt−1)I),根据重参数技巧,我们重新在标准正态分布中采样一个新的噪声ϵˉt−2,则有αt(1−αt−1)ϵt−2+1−αtϵt−1=(1−αtαt−1)ϵˉt−2
也即是
xt=αtαt−1xt−2+(1−αtαt−1)ϵˉt−2;
继续迭代下去,不难看出
xt=αtαt−1αt−2xt−3+(1−αtαt−1αt−2)ϵˉt−3;…
我们记αˉt=∏i=1Tαi,另外,由于ϵˉt−2,ϵˉt−3,…均为服从标准正态分布的噪声可简单记为ϵ,最终可得出
xt=αˉtx0+(1−αˉtϵ;
即可以基于x0和βt计算出任意时刻的xt,
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)
至此,Diffusion model的扩散过程结束,另外,一般来说对于超参数βt的设置一开始时设置得比较小,不要一下子就完全打乱原始数据的分布,当数据分布越来越接近高斯噪声时,我们就可以把βt设置得大一些,即β1<β2<⋯<βT。
2、逆扩散过程(Reverse Process)
正如前面提到逆扩散过程正是要求q(xt−1∣xt),但是很难,因此采用神经网络pθ(xt−1∣xt)来近似。实际上,pθ(xt−1∣xt) 也是一个从高斯分布中采样的过程,该高斯分布的均值与噪声样本xt以及实践t相关,记为μθ(xt,t),方差同理,记为Σθ(xt,t),则
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))
但是,我们还是不知道该怎么求。巧妙的是,虽然我们不知道q(xt−1∣xt),但是q(xt−1∣xt,x0)是可知的,可以用q(xt∣x0),q(xt−1∣x0)和q(xt∣xt−1)表示,也就是说引入x0这个问题就可解了,因此考虑用q(xt−1∣xt,x0)监督pθ(xt−1∣xt)的学习。
首先来看q(xt−1∣xt,x0)的推导,根据条件概率公式有
q(xt−1∣xt,x0)=q(x0xt)q(x0xt−1xt)
上下同乘q(x0xt−1)得
=q(x0xt−1)q(x0xt−1xt)⋅q(x0xt)q(x0xt−1)
第一项等于q(xt∣xt−1x0),又因为扩散过程是马尔可夫过程,所以q(xt∣xt−1x0)=q(xt∣xt−1);第二项上下同除q(x0),同样根据条件概率公式有,q(x0xt)q(x0xt−1)=q(x0xt)/q(x0)q(x0xt−1)/q(x0)=q(xt∣x0)q(xt−1∣x0),因此,
q(xt−1∣xt,x0)=q(xt∣xt−1)⋅q(xt∣x0)q(xt−1∣x0)
可以看到这三项都是扩散过程,根据前面扩散过程的推导以及高斯分布的概率密度函数有,
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)=σ2π(1−αt)1e−211−αt(xt−αtxt−1)2; where αt=1−βt
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)=σ2π(1−αˉt)1e−211−αˉt(xt−αˉtx0)2; where αˉt=i=1∏Tαi
q(xt−1∣x0)=N(xt−1;αˉt−1x0,(1−αˉt−1)I)=σ2π(1−αˉt−1)1e−211−αˉt−1(xt−1−αˉt−1x0)2;
注:若随机变数x服从一个均值为μ 、标准差为σ的正态分布,记为:
x∼N(μ,σ2),f(x)=σ2π1e−2σ2(x−μ)2
因此,
q(xt−1∣xt,x0)=q(xt∣xt−1)⋅q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2+1−αˉt(xt−αˉtx0)2))=exp(−21(βtxt2−2αtxtxt−1+αtxt−12+1−αˉt−1xt−12−2αˉt−1x0xt−1+αˉt−1x02−1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12−2(βtαtxt+1−αˉt−1αˉt−1x0)xt−1+C(xt,x0)))
其中,C(xt,x0)是不包含xt−1的函数,因此细节可以忽略。然后将式子中的每一项除以(βtαt+1−αˉt−11)构造成正态分布密度函数形式,可得
=exp(−211/(βtαt+1−αˉt−11)(xt−1−(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11))2)
所以,q(xt−1∣xt,x0)服从正态分布,方差与均值如下所示 ( 注意: αt=1−βt,αˉt=∏i=1Tαi ),
q(xt−1∣xt,x0)=N(xt−1;μ~(xt,x0),β~tI)
β~t=1/(βtαt+1−αˉt−11)=1/(βt(1−αˉt−1)αt−αˉt+βt)=1−αˉt1−αˉt−1⋅βt
μ~(xt,x0)=(βtαtxt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαtxt+1−αˉt−1αˉt−1x0)⋅1−αˉt1−αˉt−1⋅βt=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0
由扩散过程可知 xt=αˉtx0+(1−αˉtϵt,即x0=αˉt1(xt−(1−αˉtϵt),代入上式可得(注意:αˉt=αˉt−1⋅αt)
μ~(xt,x0)=1−αˉtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtαˉt1(xt−(1−αˉtϵt)=αt1(xt−1−αˉt1−αtϵt)
因此,
q(xt−1∣xt,x0)=N(xt−1;αt1(xt−1−αˉt1−αtϵt),1−αˉt1−αˉt−1⋅βtI)
接下来,我们就可以利用q(xt−1∣xt,x0)来监督pθ(xt−1∣xt)的训练了!
3、损失函数
要优化模型pθ(xt−1∣xt)可以考虑最大化对数似然概率,即最小化负的对数似然概率−logpθ(x0)(为什么是x0?因为扩散过程的马尔科夫链),但是由于很难对噪声空间进行积分,因此直接优化−logpθ(x0)是困难的,因此,向VAE一样,转而去优化它的变分下界LVLB,
我们知道KL散度是两个概率分布差别的非对称性度量,即KL散度大于等于零,因此有
−logpθ(x0)≤−logpθ(x0)+DKL(q(x1:T∣x0)∣∣pθ(x1:T∣x0))=−logpθ(x0)+Ex1:T∼q(x1:T∣x0)[logpθ(x0:T)/pθ(x0)q(x1:T∣x0)]=−logpθ(x0)+Eq[logpθ(x0:T)q(x1:T∣x0)+logpθ(x0)]=Eq[logpθ(x0:T)q(x1:T∣x0)]
其中,Eq[logpθ(x0:T)q(x1:T∣x0)]就是负对数似然的变分下界。或者从另外一个角度,我们可以优化真实分布与预测分布的交叉熵(cross entropy),但是由于同样的原因,优化很困难,因此求变分下界,
LCE=−Eq(x0)logpθ(x0)=−Eq(x0)log(∫pθ(x0:T)dx1:T)=−Eq(x0)log(∫q(x1:T∣x0)q(x1:T∣x0)pθ(x0:T)dx1:T)=−Eq(x0)log(Eq(x1:T∣x0)q(x1:T∣x0)pθ(x0:T))≤−Eq(x0:T)logq(x1:T∣x0)pθ(x0:T)=Eq(x0:T)logpθ(x0:T)q(x1:T∣x0)
为了方程中的每个项可解析计算,可以进一步将目标重写为几个KL散度和熵项的组合,
LVLB=Eq(x0T)[logpθ(x0:T)q(x1:T∣x0)]=Eq[logpθ(xT)∏t=1Tpθ(xt−1∣xt)∏t=1Tq(xt∣xt−1)]=Eq[−logpθ(xT)+t=1∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt∣xt−1)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlog(pθ(xt−1∣xt)q(xt−1∣xt,x0)⋅q(xt−1∣x0)q(xt∣x0))+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+t=2∑Tlogq(xt−1∣x0)q(xt∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[−logpθ(xT)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)+logq(x1∣x0)q(xT∣x0)+logpθ(x0∣x1)q(x1∣x0)]=Eq[logpθ(xT)q(xT∣x0)+t=2∑Tlogpθ(xt−1∣xt)q(xt−1∣xt,x0)−logpθ(x0∣x1)]=Eq[LTDKL(q(xT∣x0)∥pθ(xT))+t=2∑TLt−1DKL(q(xt−1∣xt,x0)∥pθ(xt−1∣xt))−L0logpθ(x0∣x1)]
变分下界可以简单表示如下:
LVLB where LTLtL0=LT+LT−1+⋯+L0=DKL(q(xT∣x0)∥pθ(xT))=DKL(q(xt∣xt+1,x0)∥pθ(xt∣xt+1)) for 1≤t≤T−1=−logpθ(x0∣x1)
其中,因为q没有参数且xT是高斯噪声,所以LT是常数,再训练的时候可以省略;另外,Denoising Diffusion Probabilistic Models(DDPM)使用一个单独的解码器N(x0;μθ(x1,1),Σθ(x1,1))来建模L0,而不是计算KL散度。
4、损失函数的重参数化
总的来说,我们希望可以学习一个神经网络可以近似逆扩散过程的条件概率分布,该神经网络表示为 pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))。我们希望训练μθ来预测μ~t=αt1(xt−1−αˉt1−αtϵt)。因为,xt在训练的过程中是已知的,所以我们的神经网络可以直接基于xt在时间步t预测高斯噪声ϵt,
μθ(xt,t) Thus xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))=N(xt−1;αt1(xt−1−αˉt1−αtϵθ(xt,t)),Σθ(xt,t))
损失函数Lt最终可以重参数化来最小化均值μ~的差异,
Lt=Ex0,ϵ[2∥Σθ(xt,t)∥221∥μ~t(xt,x0)−μθ(xt,t)∥2]=Ex0,ϵ[2∥Σθ∥221∥∥∥∥αt1(xt−1−αˉt1−αtϵt)−αt1(xt−1−αˉt1−αtϵθ(xt,t))∥∥∥∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥ϵt−ϵθ(xt,t)∥2]=Ex0,ϵ[2αt(1−αˉt)∥Σθ∥22(1−αt)2∥∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥∥2]
另外,DDPM的作者发现,省去损失函数中的加权项效果更好,
Ltsimple =Et∼[1,T],x0,ϵt[∥ϵt−ϵθ(xt,t)∥2]=Et∼[1,T],x0,,ϵt[∥∥ϵt−ϵθ(αˉtx0+1−αˉtϵt,t)∥∥2]
最终的目标函数记为:
Lsimple=Ltsimple+C
其中,C是权重无关的常数。
5、小结
扩散模型DDPM的训练和采样算法如下图所示,

论文地址:Extracting Training Data from Diffusion Models
这篇论文的意思就是扩散模型在近两年的表现牛逼上天了,但是它是不是就完美了呢?没有!他们发现扩散模型可以记住训练集中的样本,并在生成过程中进行复现。扩散模型容易受到记忆攻击,从而导致抄袭训练数据集的行为!

参考文献
[1] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
[2] https://blog.csdn.net/Little_White_9/article/details/124435560
[3] https://www.bilibili.com/video/BV1b541197HX/?spm_id_from=333.1007.top_right_bar_window_default_collection.content.click&vd_source=7b8e971b43a022cac5ad76d689c0c177