Transformer阅读笔记
本文研究基于Transformer的目标检测,相关内容参考《A Survey on Vision Transformer》.
一、Transformer-based set prediction methods
1、N. Carion et al.End-to-End Object Detection with Transformers. In ECCV, 2020.
核心:
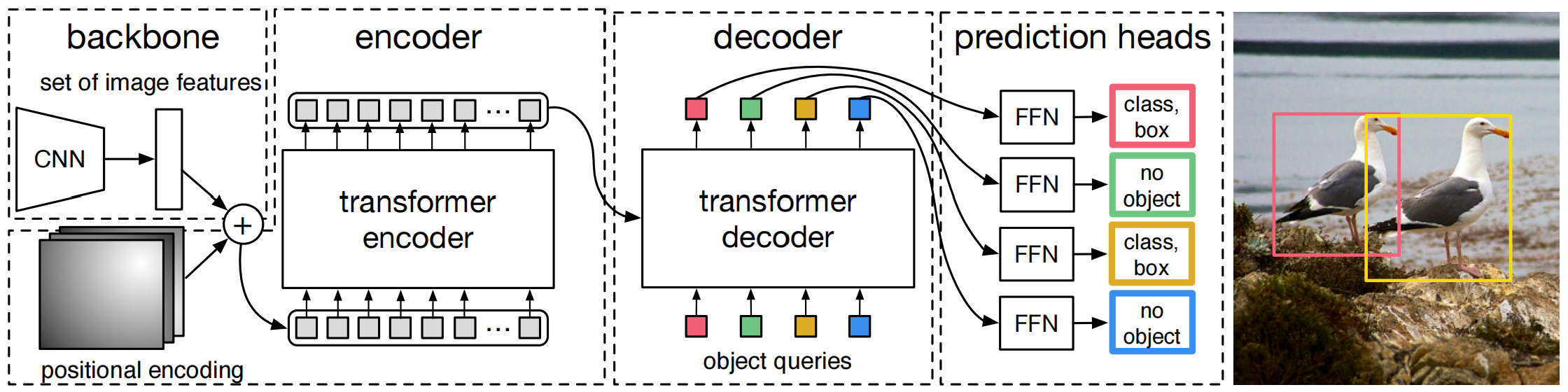
重新定义目标检测框架,CNN提取特征,将 进行32倍下采样得到输出 (),加上位置编码,输入transformer,其中decoder会通过卷积将输出变形压缩为,最后3层FNN和线性映射预测N个bounding box和类别标签,其中输入到decoder的object queries通过学习得到。(一个问题:N应该不等于HW)
DETR将目标检测建模为集合预测问题,不需要生成anchor,也不需要非极大值抑制。不需要非极大值抑制的原因是因为DETR直接将非目标的区域直接预测为no object,然后实验结果表明在decoder的第一层输出加非极大值抑制还有用,再深几层就没啥用了,所以是不需要非极大值抑制的实验发现的,并没有理论证明。
Label assignment:
Prediction 和 Ground-Truth 之间就存在一个匹配的问题(label assignment)。因为DETR采用集合预测(set prediction)的形式,两个集合之间的匹配就需要保证不受集合中元素排列组合影响,那么就变成了求集合间最优匹配的问题。本文采用 匈牙利算法(Hungarian algorithm) 求集合最优匹配问题。
Loss function 采用 Hungarian loss
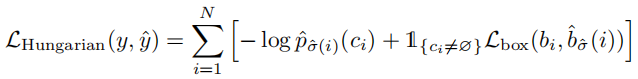
一个小技巧是在decoder的每一层都附加FNN预测头和loss。
缺点:需要非常长的训练过程,小目标检测也很差。(However, the vanilla DETR poses several challenges, specifically, longer training schedule and poor performance for small objects.)(大目标检测准确率高的原因可能是transformer的non-local特性带来的,但是这反而不利于小目标检测)
注意: Transformer 比传统卷积同等FLOPs下慢至少3倍 (Hu et al. (2019) admit such approaches are much slower in implementation than traditional convolution with the same FLOPs (at least 3× slower), due to the intrinsic limitation in memory access patterns.)
2、X. Zhu et al. Deformable detr: Deformable Transformers for End-to-End Object Detection. In ICLR, 2021.
Deformable DETR
核心: The deformable attention module attends to a small set of key positions around a reference point rather than looking at all spatial locations on image feature maps as performed by the original multi-head attention mechanism in transformer.
DETR存在的问题:
- DETR 需要非常长的训练过程才能收敛。原因有二:一是与NLP任务相比,CV任务中注意力机制的元素(elements,一般是图像特征图的像素)量过大,导致过高的计算复杂度和空间复杂度;二是注意力权重 ,当元素的数量 过大时,权重接近于0,因此需要更久的训练才能使注意力集中在特定的元素上。
- DETR 的小目标检测性能较差。原因在于transformer的特长在于捕获全局依赖,这样的非局部性对于检测大目标有效,却不利于小目标检测。
解决方案:
为了解决问题1,受可变形卷积影响,提出了可变形注意力模块。
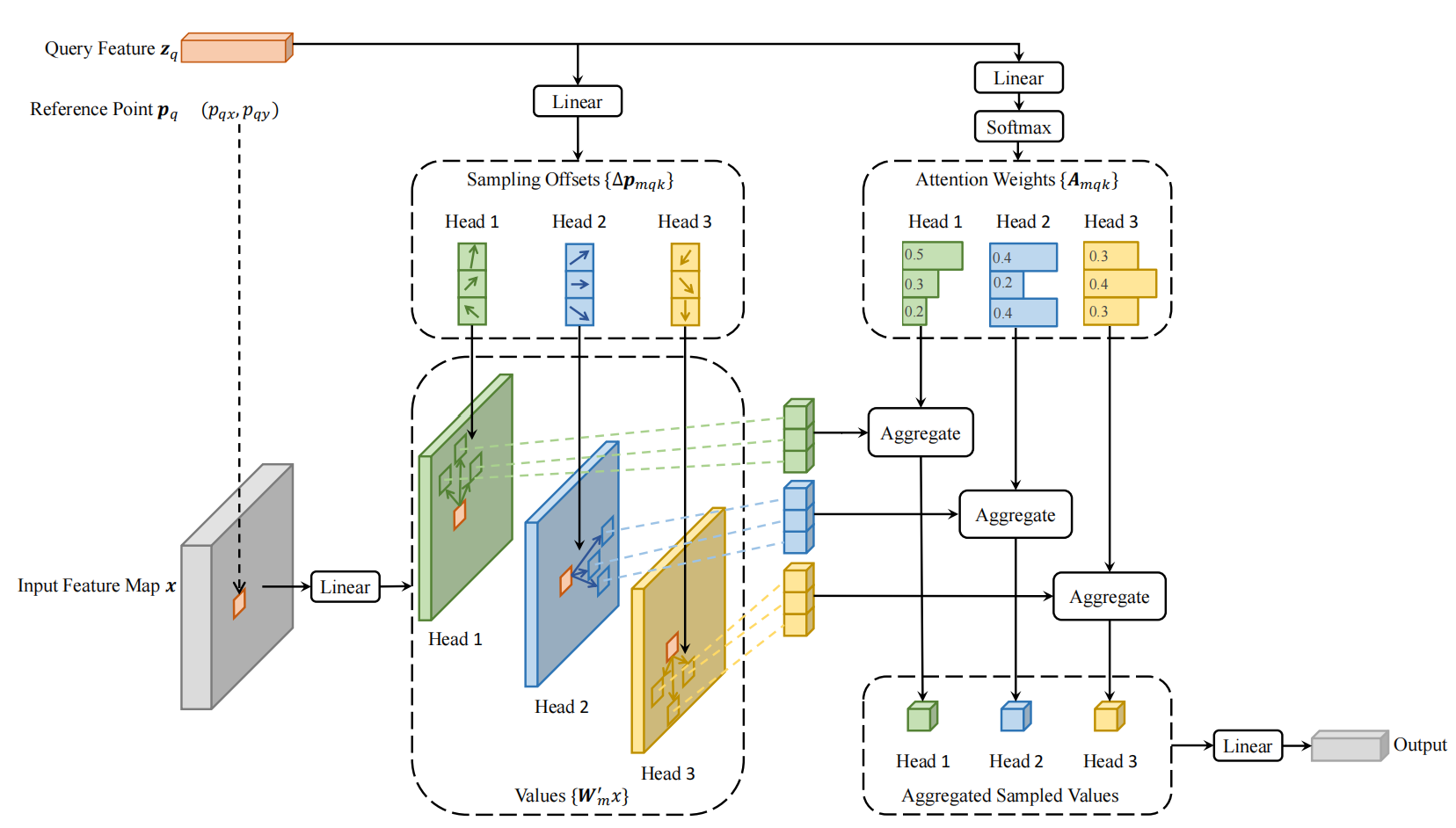
如上图所示,在注意力机制中,针对每个query,首先经过线性映射得到抽样位置的偏移量以及注意力权重,然后参考点位置加上位置偏移量得到真正的抽样位置,将抽样位置的特征(value)和注意力权重进行整合得到输出。可变形注意力机制同样采用多头注意力的形式,如上图为3头注意力。
注意:这种可变形注意力由于不对位置偏移量做任何限制,因此可以关注特征图上的任意位置,而抽样位置为有限的位置,因此同时具备了全局性和局部性。很重要!
可变形注意力数学形式定义:
给定输入特征图 ,设 是query元素的索引,对应的query的特征向量为,二维参考位点为,可变形注意力机制如下所示:
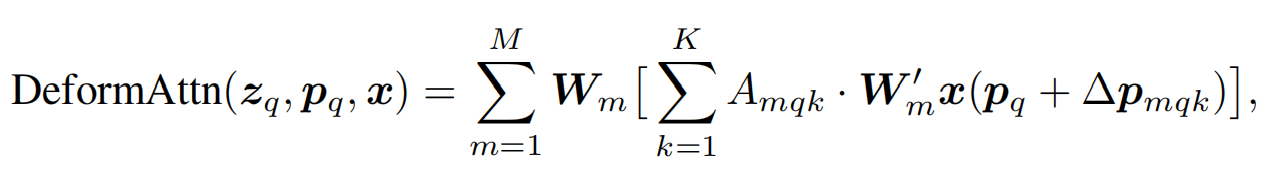
其中,是注意力头的索引;是采样的keys的索引; 是采样keys的数量()。和是通过线性映射得到的在第个注意力头第个位置的采用偏移量和注意力权重。在实现的时候,query特征向量通过线性映射网络得到通道,前通道编码了采样偏移量,剩下的通道通过得到注意力权重。注意力权重的范围,且经过归一化。采样偏移量为二维实数,且范围不限,即可以关注特征图上的任意位置。
多尺度可变形注意力
为了解决小目标检测问题,论文将可变形注意力机制拓展到多尺度特征图,需要注意的是参考点位置需要进行归一化才能在不同尺度的特征图上进行采样,即 , 将参考点位置映射到不同尺度的特征图。
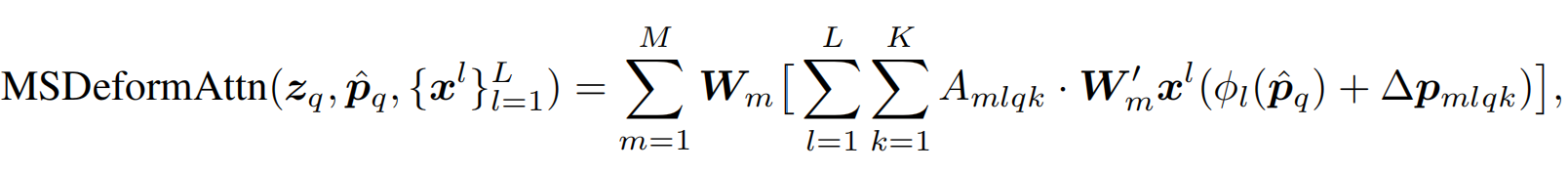
讨论: 假若将可变形注意力用于自己会议论文提出的spatial-aware和sclae-aware多尺度特征融合,那么单尺度上的可变形注意力便已经可以实现spatial-aware,但是多尺度可变形注意力却并不是scale-aware的,因为它是直接相加,
一个简单的方法是增加一个可训练的权重,即:
或者scale attention的设置为自注意力权重:
整体模型框架如下:

![]()
优点: deformable attention module 同时具备全局性和局部性,可以融合多尺度特征,更低复杂度,更快收敛,更好性能。
3、Z. Sun et al. Rethinking Transformer-based Set Prediction for Object Detection. In ICCV, pp. 3611–3620, 2021.
核心: 论文认为基于transformer的目标检测之所以收敛慢,其原因在于decoder中的 cross-attention module (就是中间跨越encoder和decoder的attention),因此论文提出了只有encoder的检测模型,而预测过程采用了新的集合预测方法——TSP-FCOS 和 TSP-RCNN,同时设计了新的 bipartite matching 方法,获得了更好的稳定性和更快的收敛速度。
研究收敛慢的原因
1、二部匹配(bipartite matching)的不稳定性导致模型收敛慢?
基于匈牙利算法的二部匹配模块是模型中的唯一组件,它的初始化往往是随机的,训练过程中的噪声也容易导致匹配的不稳定性。采用知识蒸馏(用一个预先训练的模型作为二部匹配的Teacher)与原模型比较收敛速度,如下图所示,
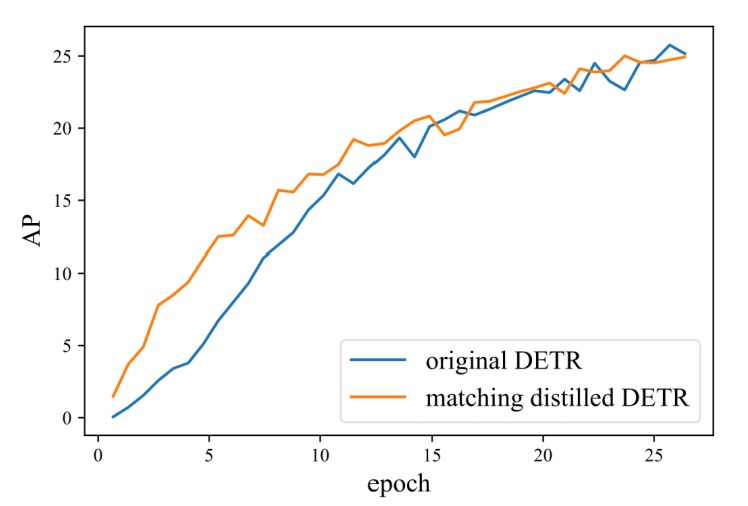
从图中可以看到,在前15epochs带知识蒸馏的DETR确实收敛更快,但是到了25epochs时优势便没有。所以说二部匹配的不稳定性有影响,但是不大。
2、注意力模块是收敛慢的主要原因?
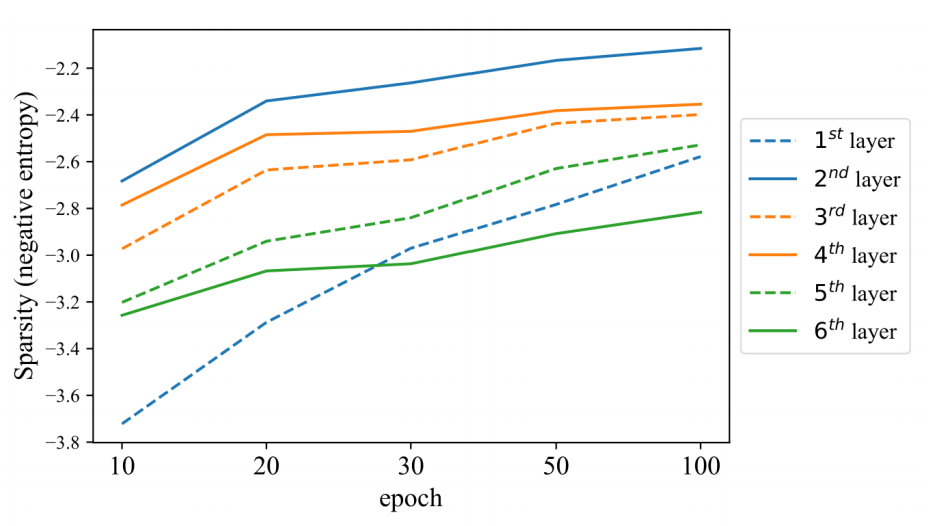
其实,经过前面的讨论,人们已经普遍相信注意力模型往往都是需要更长的训练时间。在这里作者更关注encoder和decoder之间的cross-attention模块,这个模块将encoder提取到的特征引入decoder,显然很关键。注意力模型收敛与否的标志是其离散度,注意力图可以解释为概率,所以作者采用负交叉熵作为离散度的度量,从下图中可以看到每一层神经网络的离散度都在上升,到了100epochs都没有收敛,显然这就是导致收敛慢的主要原因。
那么,cross-attention模块收敛慢,我们不要行不行?作者直接去掉了decoder,如下图所示,
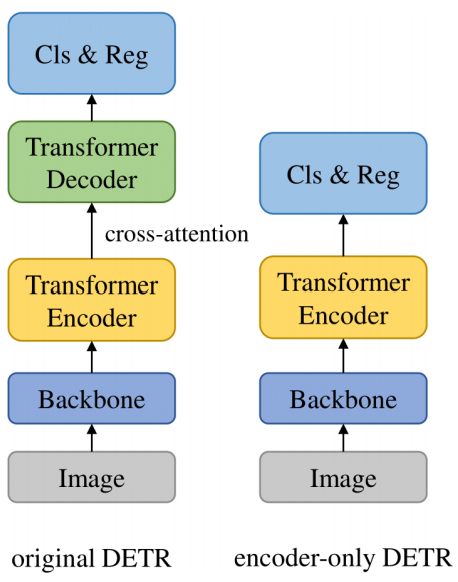
然后,看看结果,如下图所示,可以看到去掉decoder之后AP几乎不变,而且在小目标检测和中等目标检测上还相对更好,尤其是小目标检测,但是大目标检测却面临了准确率下降(很神奇)。作者认为其原因可能是:A potential interpretation, we think, is that a large object may include too many potentially matchable feature points, which are diffificult for the sliding point scheme in the encoder-only DETR to handle. Another possible reason is that a single feature map processed by encoder is not robust for predicting objects of different scales .
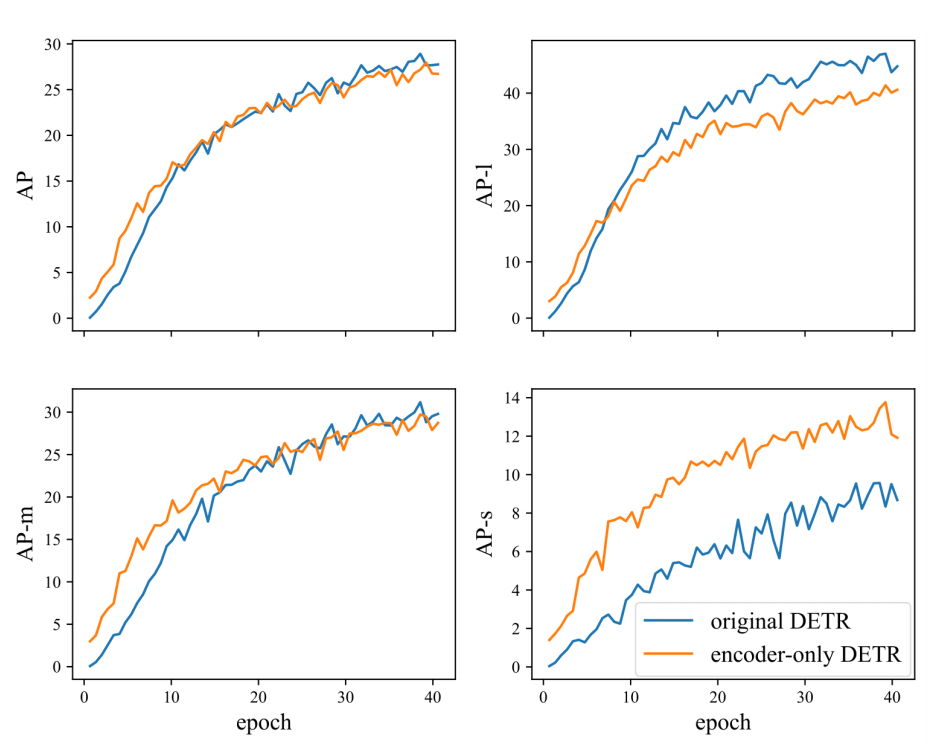
所提出的方法:
作者找到了他们认为的DETR收敛慢的原因,但是他们提出来的改进方法并不优雅!
上面说到直接去掉decoder会导致大目标检测性能下降,说明不能很好应对多尺度目标检测,那怎么办?加FPN,如下图所示。加上FPN之后,考虑到FCOS模型有个特征选择的模块,就是Feature of Interest,那也加上。得到的特征加上位置编码然后输入encoder中,最后输出预测解决。最后考虑到二部匹配不太稳,那就加上FCOS的匹配规则作为二部匹配的约束条件。这就是TSP-FCOS模型,这么一整,感觉就是FCOS模型换了个检测头。同样,仿照Faster R-CNN加上RPN,同时借鉴Faster R-CNN的匹配规则作为约束条件,这就是TSP-RCNN模型。
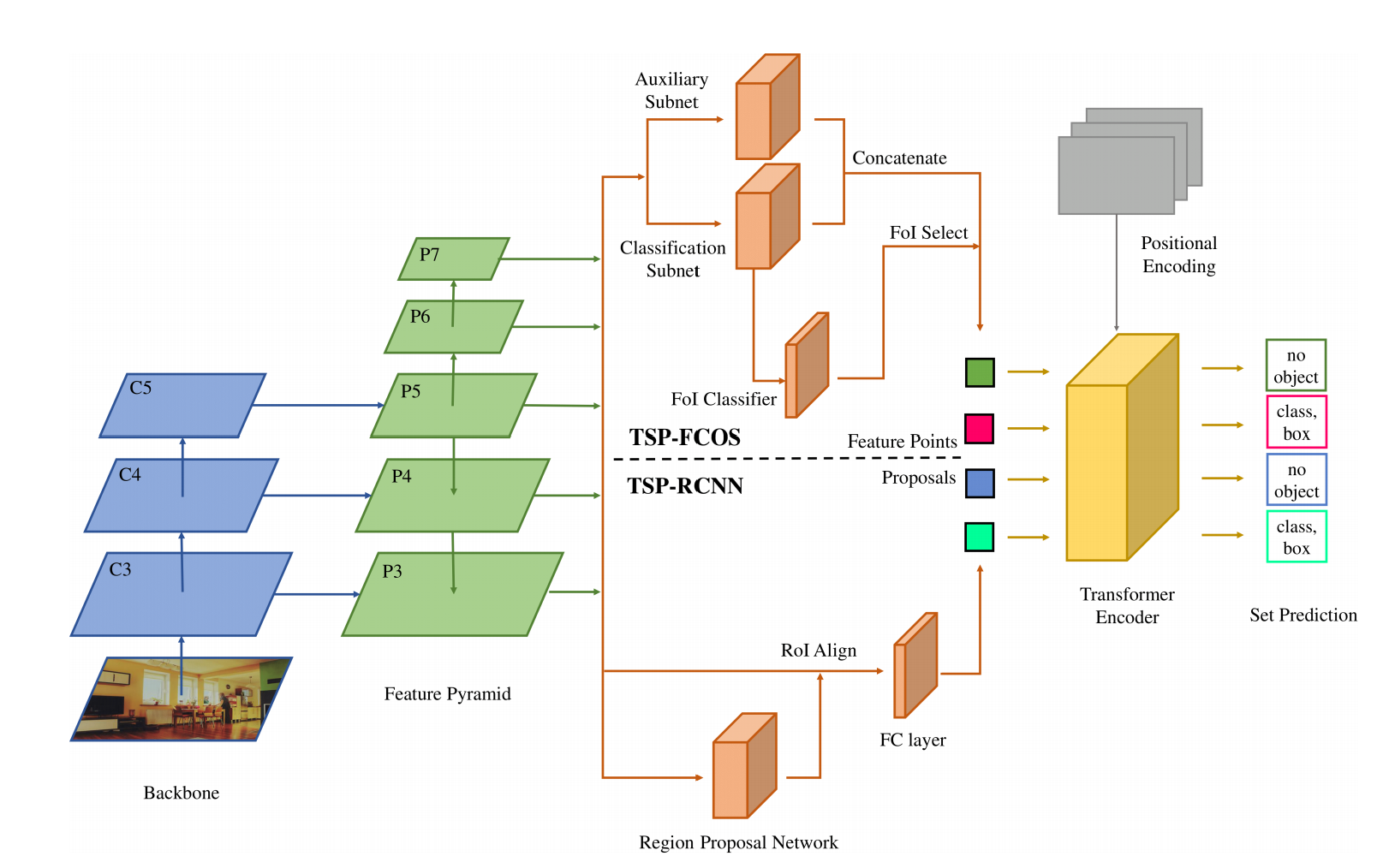
意义: 我觉得这篇文章最大的意义就是证明了去掉decoder对模型性能影响不大,同时证明了FPN对检测不同尺度目标的重要性。但是我想把第一步主干网络特征提取也简化了,不然太不优雅。
4、M. Zheng et al. End-to-end object detection with adaptive clustering transformer. In BMVC, 2021.
核心: 提出了Adaptive Clustering Transformer (ACT) 替换自注意力模块。ACT adaptively clusters the query features using a locality sensitivity hashing (LSH) method and broadcasts the attention output to the queries represented by the selected prototypes。可以以轻微性能下降为代价极大降低计算复杂度。
同样,这篇文章的主要目的也是提高模型收敛速度。
Motivation:
1、Encoder中的注意力冗余
如下图所示,左边是图中3个不同位置的注意力图,可以发现和的注意力图很相似,这是因为这两个点都在同一个目标上而且相距较近,与此相反的注意力图则完全不同。现和的注意力图相似恰恰说明encoder中注意力的计算存在大量冗余。
我们知道注意力计算的复杂度就是,所以要降低复杂度就要减少或的数量,然后根据刚刚的观察和的注意力计算存在冗余,那么我们完全可以用代替从而减少 的数量。具体的做法就是对做聚类,然后拿每个类的原型()去做注意力计算,然后将梯度更新广播到类中的每个点上。
点评: 很有意思的想法,和Deformable DETR形成互补。Deformable DETR认为给定一个不是对所有的都要注意到,其中很多的权重都为零,这就是局部性。所以Deformable DETR通过预测需要注意的少量的,从而降低了计算复杂度。我认为这两者可以结合起来。

提出的方法:
作者将这种注意力机制称为自适应聚类注意力(Adaptive Clustering Attention),用于替换encoder中的attention 模块,decoder保持不变。自适应聚类注意力的工作原理很简单,如下图左所示,input features同样是先线性映射成,然后对进行聚类得到每个类的原型(),将与计算,然后与相乘,得到输出,最后进行广播。
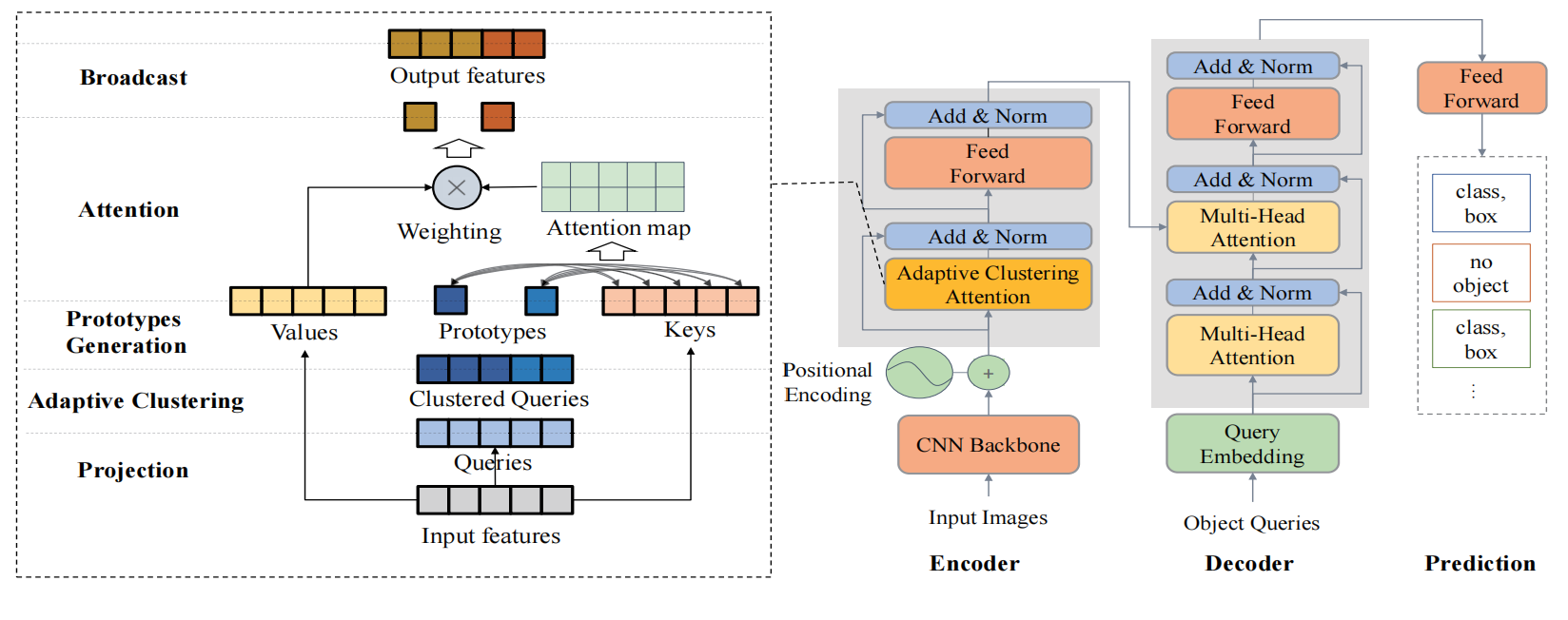
关键在聚类,但是需要注意,每个网络层的特征分布是不一样的,所以需要自适应聚类。文章采用的是Exact Euclidean Locality Sensitive Hashing (E2LSH)进行聚类,它可以让所有距离小于ε的向量以大于p的概率落入同一哈希桶中(let all vectors with a distance less
than fall into the same hash bucket with a probability greater than ),哈希函数如下所示:
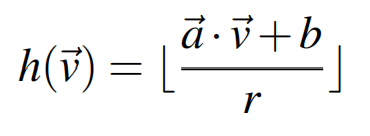
其中,都是超参数,控制着超平面的间距,和 都是随机变量,满足正态分布,满足均匀分布。为了增加结果的可信度,迭代计算回哈希值,为常数,。落入同一哈希桶中的向量具有同一哈希值,距离越近的向量落入同一哈希桶的概率越大。至此,我们实现了自适应聚类。
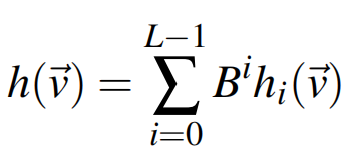
聚类完成后计算,记为, 为所在的簇的索引,计算某个簇的其实就是计算改簇的均值,如计算第个簇的如下所示,
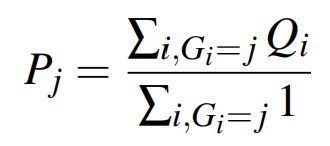
剩下的注意力计算和广播就比较简单了,如下所示,
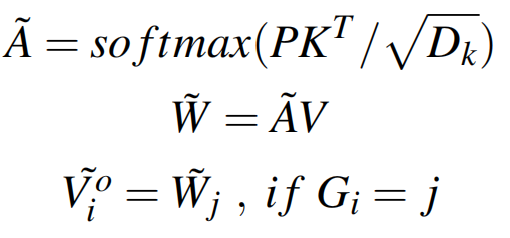
必须注意的是: 虽然极大地降低了计算复杂度,但是性能轻微下降,所以这个方法更应该归类于transformer轻量化研究。
为了恢复检测精度,作者采用多任务知识蒸馏,如下图所示,
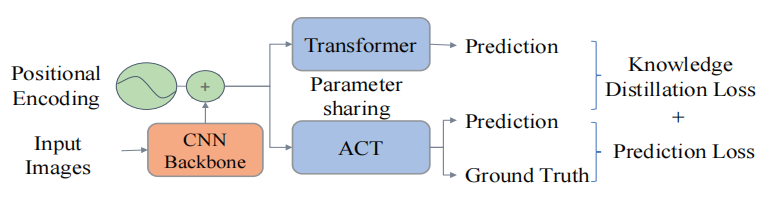
最终,精度损失控制在。
5、P. Gao et al. Fast convergence of detr with spatially modulated co-attention. In ICCV, 2021.
核心: 主要提出了 Spatially Modulated Co-Attention (SMCA) mechanism,其作用是constraining co-attention responses to be high near initially estimated bounding box locations. 可以加快收敛速度
6、Z. Yao et al. Efficient detr: Improving end-to-end object detector with dense prior.arXiv:2104.01318, 2021.
核心: 论文认为DETR收敛慢的原因在于初始化的方法不对,提出通过额外的region proposal network引进先验知识,(To this end, they proposed the Efficient DETR to incorporatethe dense prior into the detection pipeline via an additional region proposal network.)通过这样的初始化,只需要一层decoder 就可以达到相当的检测性能。
7、Xia, Zhuofan et al. “Vision Transformer with Deformable Attention.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022): 4784-4793.
这篇论文的代码和论文自身讲的对不上,怀疑有问题!
二、Transformer-based backbone method
1、J. Beal et al. Toward transformer-based object detection.arXiv:2012.09958, 2020.
核心: 将transformer作为主干网络结合到传统目标检测框架中。首先把图片划分为patch,如何输入到transformer提取特征,得到的embedding按照空间信息重新组合然后输入到检测头中进行目标检测。具有代表性的transformer主干网络,如: Swin Transformer
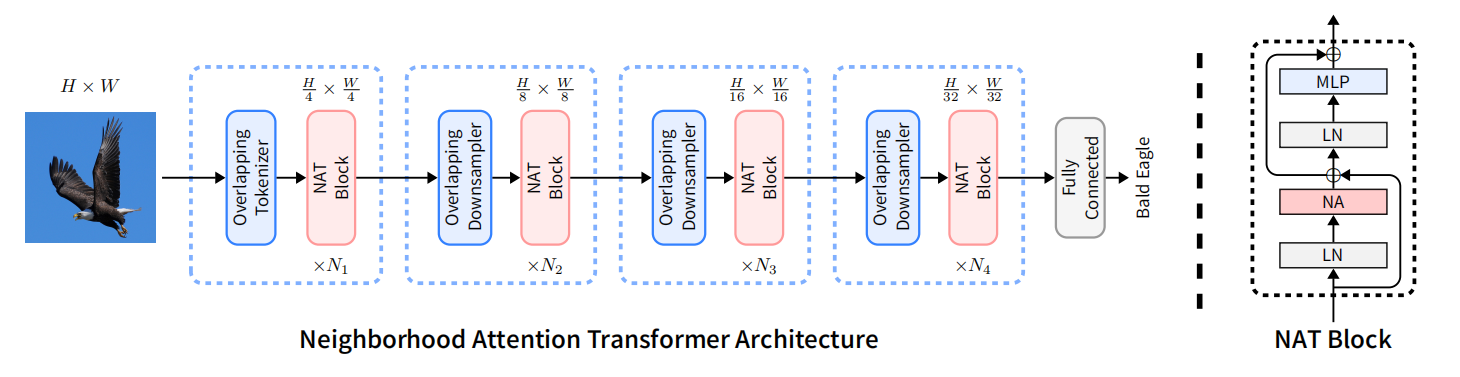
2、Hassani A, Walton S, Li J, et al. Neighborhood Attention Transformer. arXiv preprint arXiv:2204.07143, 2022.
这是一个值得关注的transformer主干网络!
Neighborhood Attention (NA)
给定输出特征图 ,
首先进行一维展开得到 ,
将 进行现象映射得到query ,key ,value ,
为每个query找到它的邻居,记为 ,规模为,如下图所示:

记第个query的第个邻居为,且它们的相对位置偏置为,则注意力权重计算如下所示:
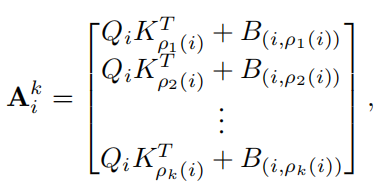
同样将对应的value找出来,
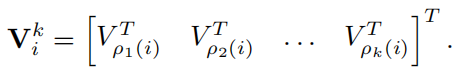
最后,作注意力计算得最终结果,
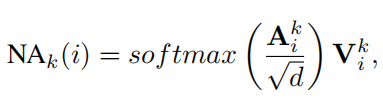
Neighborhood Attention和Self Attention的示意图如下:
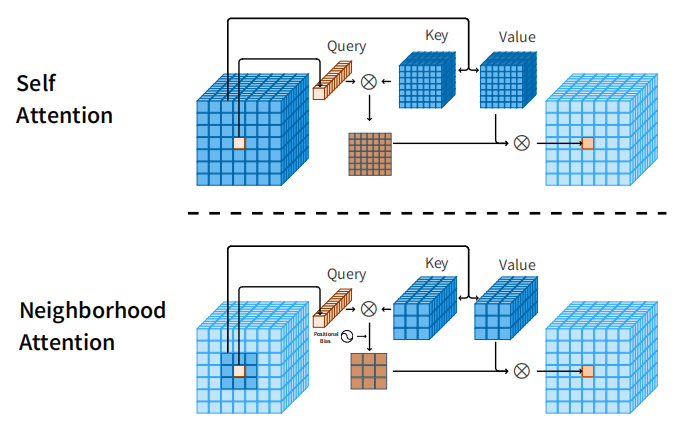
Note: Neighborhood Attention的关键在于如何快速找出neighbor,但是论文里并没有过多讲述,而是写成了cuda算子,我看不懂
3、Hassani, Ali and Humphrey Shi. “Dilated Neighborhood Attention Transformer” ArXiv abs/2209.15001 (2022): n. pag.
借鉴空洞卷积实现的版本,可以有效捕获长距离依赖!
三、Light-Weight transformer
1、Huang T, Huang L, You S, et al. Towards Light-Weight Convolution-Free Vision Transformers. arXiv preprint arXiv:2207.05557, 2022.
2、Shen Z, Zhang M, Zhao H, et al. Efficient attention: Attention with linear complexities[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021: 3531-3539.
3、Lee, S.H., Lee, S., & Song, B.C. (2021). Vision Transformer for Small-Size Datasets. ArXiv, abs/2112.13492.
思考:
-
目前为止,看到的基于transformer的目标检测模型都是考虑如何改进从而提高收敛速度,但是这并不会降低计算复杂度,考虑到海洋机器人有限的计算资源,我们需要的不仅是收敛快,计算速度也要快(即实时计算)。
-
目前位置的transformer模型都需要一个CNN(例如ResNet)先提取特征,那这样看,与其说transformer是检测模型的主干网络,不如说是检测模型的检测头。所以说基于transformer的模型的优势是在检测头考虑了全局依赖(而且这种全局依赖不利于小目标检测)。我希望做到的是先用patch embedding,再用deformable transformer作为主干网络提取特征。(目前采用Neighborhood Attention 作为主干网络提取特征)
-
特征金字塔对于多尺度目标检测依然十分重要不能丢掉,考虑自己的会议论文提出的方法。(刚刚发现Multi-scale Deformable Self-Attention完全符合我会议论文里说的多尺度特征应该spatial-aware和scale-aware)
-
transformer的另外一个优势是端到端的集合预测模式(set prediction)。object query可以看作是数据集的统计信息,在YOLOX中丢弃decouple head,采用decoder作为检测头,引入object query,改造成端到端的集合预测,达到NMS-free目的。(可能需要放弃这个,因为这种模式采用one-2-one的label assignment,会导致正负样本不均衡,不利于小目标检测)
- 一、Transformer-based set prediction methods
- 1、N. Carion et al.End-to-End Object Detection with Transformers. In ECCV, 2020.
- 2、X. Zhu et al. Deformable detr: Deformable Transformers for End-to-End Object Detection. In ICLR, 2021.
- 3、Z. Sun et al. Rethinking Transformer-based Set Prediction for Object Detection. In ICCV, pp. 3611–3620, 2021.
- 4、M. Zheng et al. End-to-end object detection with adaptive clustering transformer. In BMVC, 2021.
- 5、P. Gao et al. Fast convergence of detr with spatially modulated co-attention. In ICCV, 2021.
- 6、Z. Yao et al. Efficient detr: Improving end-to-end object detector with dense prior.arXiv:2104.01318, 2021.
- 7、Xia, Zhuofan et al. “Vision Transformer with Deformable Attention.” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022): 4784-4793.
- 二、Transformer-based backbone method
- 1、J. Beal et al. Toward transformer-based object detection.arXiv:2012.09958, 2020.
- 2、Hassani A, Walton S, Li J, et al. Neighborhood Attention Transformer. arXiv preprint arXiv:2204.07143, 2022.
- 3、Hassani, Ali and Humphrey Shi. “Dilated Neighborhood Attention Transformer” ArXiv abs/2209.15001 (2022): n. pag.
- 三、Light-Weight transformer
- 1、Huang T, Huang L, You S, et al. Towards Light-Weight Convolution-Free Vision Transformers. arXiv preprint arXiv:2207.05557, 2022.
- 2、Shen Z, Zhang M, Zhao H, et al. Efficient attention: Attention with linear complexities[C]//Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2021: 3531-3539.
- 3、Lee, S.H., Lee, S., & Song, B.C. (2021). Vision Transformer for Small-Size Datasets. ArXiv, abs/2112.13492.
- 思考: