mmdetection-3.x学习笔记——RTMDet模型检测头源码阅读
RTMDet模型的检测头同样基于YOLOX Head,采用分类分支和回归分支解耦的形式,目的就是缓解分类和回归两个任务之间的冲突。不同的是YOLOX 在3个尺度特征图上都共享同一个检测头以降低参数量,但是这也会削弱模型的能力。大多数模型为了提升模型能力都不共享检测头。RTMDet选择了中间策略,不同尺度特征图只共享卷积层,配备独立的BN层、激活层以及最后特征图到预测结果的预测层。当然RTMDet也实现了全共享检测头的RTMDetHead,不过默认采用独立BN层的RTMDetSepBNHead,配置文件如下:
bbox_head = dict(
type="RTMDetSepBNHead",
num_classes=80,
in_channels=256,
stacked_convs=2,
feat_channels=256,
anchor_generator=dict(type="MlvlPointGenerator", offset=0, strides=[8, 16, 32]),
bbox_coder=dict(type="DistancePointBBoxCoder"),
loss_cls=dict(type="QualityFocalLoss", use_sigmoid=True, beta=2.0, loss_weight=1.0),
loss_bbox=dict(type="GIoULoss", loss_weight=2.0),
with_objectness=False,
exp_on_reg=True,
share_conv=True,
pred_kernel_size=1,
norm_cfg=dict(type="SyncBN"),
act_cfg=dict(type="SiLU", inplace=True),
)
train_cfg = (
dict(
assigner=dict(type="DynamicSoftLabelAssigner", topk=13),
allowed_border=-1,
pos_weight=-1,
debug=False,
),
)
RTMDetSepBNHead的网络结构
除却参数共享设置不一致之外,RTMDetSepBNHead和YOLOX Head的结构基本一样,另外,YOLOX Head的Objectness分支在RTMDetSepBNHead被设为了可选选项,而且在目标检测的模型配置文件中都没有启用(with_objectness=False),也就是去掉 Objectness 分支,进一步将 Head 轻量化。。
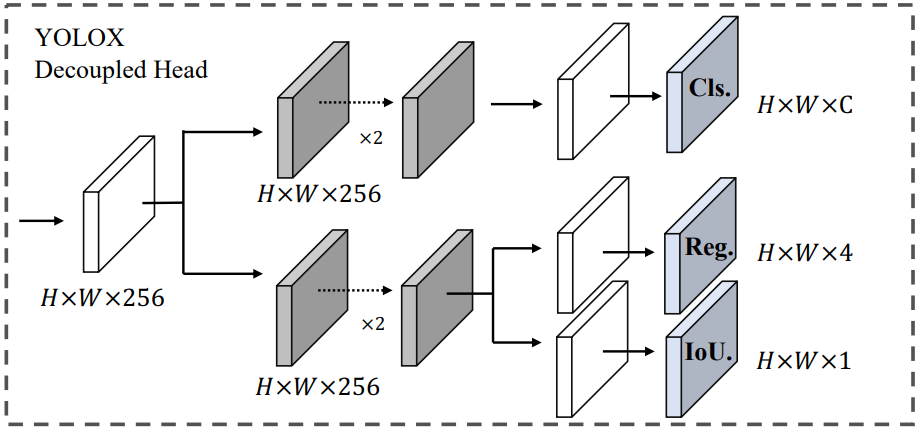
由上图可知,检测头分分类和回归两个分支,每个分支由2个卷积层加一个预测层,可选的Objectness分支附在回归分支上,检测头网络由def _init_layers(self) -> None构建,具体代码如下:
def _init_layers(self) -> None:
"""Initialize layers of the head."""
conv = DepthwiseSeparableConvModule if self.use_depthwise else ConvModule
self.cls_convs = nn.ModuleList() # 分类分支的卷积层
self.reg_convs = nn.ModuleList() #回归分支的卷积层
self.rtm_cls = nn.ModuleList() # 分类分支的预测层
self.rtm_reg = nn.ModuleList() # 回归分支的预测层
if self.with_objectness: # 如果启用Objectness分支
self.rtm_obj = nn.ModuleList() # Objectness分支的预测层
# 遍历strides,也就是遍历不同尺度的特征图,RTMDetSepBNHead选择先为每个尺度的
# 特征图构建独立的检测头
for n in range(len(self.prior_generator.strides)):
cls_convs = nn.ModuleList()
reg_convs = nn.ModuleList()
for i in range(self.stacked_convs): # 遍历卷积层层数并构建
chn = self.in_channels if i == 0 else self.feat_channels
cls_convs.append(
conv(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
)
)
reg_convs.append(
conv(
chn,
self.feat_channels,
3,
stride=1,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg,
act_cfg=self.act_cfg,
)
)
self.cls_convs.append(cls_convs)
self.reg_convs.append(reg_convs)
self.rtm_cls.append(
nn.Conv2d(
self.feat_channels,
self.num_base_priors * self.cls_out_channels,
self.pred_kernel_size, # 一般设为1
padding=self.pred_kernel_size // 2,
)
)
self.rtm_reg.append(
nn.Conv2d(
self.feat_channels,
self.num_base_priors * 4,
self.pred_kernel_size,
padding=self.pred_kernel_size // 2,
)
)
if self.with_objectness:
self.rtm_obj.append(
nn.Conv2d(
self.feat_channels,
1,
self.pred_kernel_size,
padding=self.pred_kernel_size // 2,
)
)
为每个尺度特征图构建检测头之后,采用self.share_conv控制是否共享卷积层,具体代码如下:
if self.share_conv:
for n in range(len(self.prior_generator.strides)): # 遍历特征图的尺度
for i in range(self.stacked_convs): # 遍历卷积层
#将第n个尺度对应的检测头中第i卷积模块的卷积层都指向第0个检测头中第i卷积模块的
#卷积层,从而实现卷积层共享,可以通过id(self.cls_convs[n][i].conv)验证
self.cls_convs[n][i].conv = self.cls_convs[0][i].conv
self.reg_convs[n][i].conv = self.reg_convs[0][i].conv
RTMDetSepBNHead采用MMCV自定义的ConvModule来构建卷积模块,其为每个网络层定义了名字,卷积层为conv,BN层为bn,激活层为activate,如下所示,因此可以用self.cls_convs[n][i].conv的方式获取该卷积模块的卷积层,
(0): ConvModule(
#params: 0.15M, #flops: 1.24G, #acts: 1.08M
(conv): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
#params: 0.15M, #flops: 1.24G, #acts: 1.08M
)
(bn): _BatchNormXd(
128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True
#params: 0.26K, #flops: 1.64M, #acts: 0
)
(activate): SiLU(inplace=True)
)
1、RTMDetSepBNHead的输出
由上面YOLOX Head的图,我们可以知道,YOLOX为每个尺度的特征图生成一个的分类预测图,其中和为特征图的高和宽,为目标类别总数,当然这里忽略了batch sizes,而且在采用卷积层为预测层的实现中实际输出维度为。另外,生成的回归分支预测图为,objectness分支的预测图为。回到RTMDetSepBNHead中,其与YOLOX Head的区别在于:
(1)引入self.num_base_priors,可以控制模型为特征图的每个网格点预测多个边界框
(2)在启用objectness分支时,将objectness预测和分类预测合并
所有RTMDetSepBNHead每个尺度的特征图只有两个输出,所有的尺度的输出再组成元组,具体参考下面的注释,需要注意一点就是回归的边界框为 格式,结合采用的编解码过程(mmdet.DistancePointBBoxCoder)来看,这并不是左上角和右下角坐标,而是中心点到4边的距离(top, bottom, left, right),需要经过解码过程才得到左上角和右下角坐标。
def forward(self, feats: Tuple[Tensor, ...]) -> tuple:
"""Forward features from the upstream network.
Args:
feats (tuple[Tensor]): Features from the upstream network, each is
a 4D-tensor.
Returns:
tuple: Usually a tuple of classification scores and bbox prediction
- cls_scores (tuple[Tensor]): Classification scores for all scale
levels, each is a 4D-tensor, the channels number is
num_anchors * num_classes. Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
- bbox_preds (tuple[Tensor]): Box energies / deltas for all scale
levels, each is a 4D-tensor, the channels number is
num_anchors * 4. Decoded box for each scale level with shape
(N, num_anchors * 4, H, W) in [tl_x, tl_y, br_x, br_y] format.
"""
cls_scores = []
bbox_preds = []
# 遍历所有尺度特征图
for idx, (x, stride) in enumerate(zip(feats, self.prior_generator.strides)):
cls_feat = x
reg_feat = x
# 分类分支
for cls_layer in self.cls_convs[idx]:
cls_feat = cls_layer(cls_feat)
cls_score = self.rtm_cls[idx](cls_feat) # 分类预测输出
# 回归分支
for reg_layer in self.reg_convs[idx]:
reg_feat = reg_layer(reg_feat)
# objectness分支
if self.with_objectness:
objectness = self.rtm_obj[idx](reg_feat)
# 将objectness预测和分类预测合并
# 这应该是源于TOOD(https://arxiv.org/abs/2108.07755v3)
# 将分类分数以及 IOU 相乘计算 Cost 矩阵进行标签匹配
# sigmoid_geometric_mean(cls_score, objectness) 实现两个sigmoid连续相乘
# 即 z = (x_sigmoid * y_sigmoid).sqrt()
# inverse_sigmoid() 即sigmoid的反函数
cls_score = inverse_sigmoid(sigmoid_geometric_mean(cls_score, objectness))
if self.exp_on_reg: # bbox的两种解码方式
reg_dist = self.rtm_reg[idx](reg_feat).exp() * stride[0]
else:
reg_dist = self.rtm_reg[idx](reg_feat) * stride[0]
cls_scores.append(cls_score)
bbox_preds.append(reg_dist)
return tuple(cls_scores), tuple(bbox_preds)
2、获得points先验
获得points先验, 其实就是获取特征图每个点在原图的坐标,RTMDet采用的是MlvlPointGenerator,
anchor_generator=dict(type="MlvlPointGenerator", offset=0, strides=[8, 16, 32]),
通过MlvlPointGenerator.grid_priors()获取先验,计算过程很简单,公式为:
调用代码:
multi_level_anchors = self.prior_generator.grid_priors(
featmap_sizes, device=device, with_stride=True)
RTMDet 在3个尺度的特征图上进行检测,那么 multi_level_anchors的维度应该类似于
def grid_priors()函数代码
def grid_priors(self,
featmap_sizes: List[Tuple],
dtype: torch.dtype = torch.float32,
device: DeviceType = 'cuda',
with_stride: bool = False) -> List[Tensor]:
"""Generate grid points of multiple feature levels.
Args:
featmap_sizes (list[tuple]): List of feature map sizes in
multiple feature levels, each size arrange as
as (h, w). 例:[(8, 8), (16, 16), (32, 32)]
dtype (:obj:`dtype`): Dtype of priors. Defaults to torch.float32.
device (str | torch.device): The device where the anchors will be
put on.
with_stride (bool): Whether to concatenate the stride to
the last dimension of points.
Return:
list[torch.Tensor]: Points of multiple feature levels.
The sizes of each tensor should be (N, 2) when with stride is
``False``, where N = width * height, width and height
are the sizes of the corresponding feature level,
and the last dimension 2 represent (coord_x, coord_y),
otherwise the shape should be (N, 4),
and the last dimension 4 represent
(coord_x, coord_y, stride_w, stride_h).
"""
assert self.num_levels == len(featmap_sizes)
multi_level_priors = []
for i in range(self.num_levels):
priors = self.single_level_grid_priors(
featmap_sizes[i],
level_idx=i,
dtype=dtype,
device=device,
with_stride=with_stride)
multi_level_priors.append(priors)
return multi_level_priors
def single_level_grid_priors(self,
featmap_size: Tuple[int],
level_idx: int,
dtype: torch.dtype = torch.float32,
device: DeviceType = 'cuda',
with_stride: bool = False) -> Tensor:
"""Generate grid Points of a single level.
Note:
This function is usually called by method ``self.grid_priors``.
Args:
featmap_size (tuple[int]): Size of the feature maps, arrange as
(h, w).
level_idx (int): The index of corresponding feature map level.
dtype (:obj:`dtype`): Dtype of priors. Defaults to torch.float32.
device (str | torch.device): The device the tensor will be put on.
Defaults to 'cuda'.
with_stride (bool): Concatenate the stride to the last dimension
of points.
Return:
Tensor: Points of single feature levels.
The shape of tensor should be (N, 2) when with stride is
``False``, where N = width * height, width and height
are the sizes of the corresponding feature level,
and the last dimension 2 represent (coord_x, coord_y),
otherwise the shape should be (N, 4),
and the last dimension 4 represent
(coord_x, coord_y, stride_w, stride_h).
"""
feat_h, feat_w = featmap_size
stride_w, stride_h = self.strides[level_idx]
# 生成一个行状为(0, feat_w)的列表,乘以stride,映射回原图
shift_x = (torch.arange(0, feat_w, device=device) +
self.offset) * stride_w
# keep featmap_size as Tensor instead of int, so that we
# can convert to ONNX correctly
shift_x = shift_x.to(dtype)
shift_y = (torch.arange(0, feat_h, device=device) +
self.offset) * stride_h
# keep featmap_size as Tensor instead of int, so that we
# can convert to ONNX correctly
shift_y = shift_y.to(dtype)
# 获得网格点,就是每个anchor的中心点在原图的坐标
shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
if not with_stride:
shifts = torch.stack([shift_xx, shift_yy], dim=-1)
else: # 把strides带上
# use `shape[0]` instead of `len(shift_xx)` for ONNX export
stride_w = shift_xx.new_full((shift_xx.shape[0], ),
stride_w).to(dtype)
stride_h = shift_xx.new_full((shift_yy.shape[0], ),
stride_h).to(dtype)
shifts = torch.stack([shift_xx, shift_yy, stride_w, stride_h],
dim=-1)
all_points = shifts.to(device)
return all_points
def _meshgrid(self,
x: Tensor,
y: Tensor,
row_major: bool = True) -> Tuple[Tensor, Tensor]:
yy, xx = torch.meshgrid(y, x)
if row_major:
# warning .flatten() would cause error in ONNX exporting
# have to use reshape here
return xx.reshape(-1), yy.reshape(-1)
else:
return yy.reshape(-1), xx.reshape(-1)
valid_flags
(个人理解,还不确定是否准确)由于在pytorch的dataloader组装batch时,也就是调用collate_fn 函数时,填充了大量黑边,所以在黑边上的point不用计算loss,可以忽略,节省算力。因此valid_flags返回有效的point索引。
我认为这一步只能忽略组batch时添加的padding,而在数据增广流程中调用的Pad类添加的padding是无法去掉的。所以在RTMDet中由于在数据增广流程中调用Pad类将每张图片padding成(640, 640)大小,那么组batch时就不用padding了,那么这里的每个points先验都是有效的。
collate_fn (Callable, optional) – merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
def valid_flags(self,
featmap_sizes: List[Tuple[int, int]],
pad_shape: Tuple[int],
device: DeviceType = 'cuda') -> List[Tensor]:
# pad_shape是有效的特征图大小,是指Pad后的size,collate_fn之前
"""Generate valid flags of points of multiple feature levels.
Args:
featmap_sizes (list(tuple)): List of feature map sizes in
multiple feature levels, each size arrange as
as (h, w).
pad_shape (tuple(int)): The padded shape of the image,
arrange as (h, w).
device (str | torch.device): The device where the anchors will be
put on.
Return:
list(torch.Tensor): Valid flags of points of multiple levels.
"""
assert self.num_levels == len(featmap_sizes)
multi_level_flags = []
for i in range(self.num_levels):
point_stride = self.strides[i]
feat_h, feat_w = featmap_sizes[i]
h, w = pad_shape[:2]
# 获得有效的特征图的高和宽
valid_feat_h = min(int(np.ceil(h / point_stride[1])), feat_h)
valid_feat_w = min(int(np.ceil(w / point_stride[0])), feat_w)
flags = self.single_level_valid_flags((feat_h, feat_w),
(valid_feat_h, valid_feat_w),
device=device)
multi_level_flags.append(flags)
return multi_level_flags
def single_level_valid_flags(self,
featmap_size: Tuple[int, int],
valid_size: Tuple[int, int],
device: DeviceType = 'cuda') -> Tensor:
"""Generate the valid flags of points of a single feature map.
Args:
featmap_size (tuple[int]): The size of feature maps, arrange as
as (h, w).
valid_size (tuple[int]): The valid size of the feature maps.
The size arrange as as (h, w).
device (str | torch.device): The device where the flags will be
put on. Defaults to 'cuda'.
Returns:
torch.Tensor: The valid flags of each points in a single level \
feature map.
"""
feat_h, feat_w = featmap_size
valid_h, valid_w = valid_size
assert valid_h <= feat_h and valid_w <= feat_w
# 有效位置设置为1,否则为0
valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
valid_x[:valid_w] = 1
valid_y[:valid_h] = 1
valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
valid = valid_xx & valid_yy
return valid
3、将分类分支的预测结果展成以为并将同一张图片的预测结果串联起来
flatten_cls_scores = torch.cat([
cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
self.cls_out_channels)
for cls_score in cls_scores
], 1)
此时flatten_cls_scores的维度应该是,num_imgs就是batch_size,num_priors应该等于3张特征图维度相加,即
4、将回归分支预测的中心点到四边的距离解码成bbox并将同一张图片的预测结果串联起来
decoded_bboxes = []
for anchor, bbox_pred in zip(anchor_list[0], bbox_preds):
anchor = anchor.reshape(-1, 4)
bbox_pred = bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
bbox_pred = distance2bbox(anchor, bbox_pred)
decoded_bboxes.append(bbox_pred)
flatten_bboxes = torch.cat(decoded_bboxes, 1)
RTNDet采用的编解码器为DistancePointBBoxCoder,
bbox_coder=dict(type="DistancePointBBoxCoder")
首先来看一下从预测距离转化成真实的边界框的左上坐标和右下坐标的解码过程。
def distance2bbox(
points: Tensor,
distance: Tensor,
....
) -> Tensor:
"""Decode distance prediction to bounding box.
Args:
points (Tensor): Shape (B, N, 2) or (N, 2). 网格中心点坐标
distance (Tensor): Distance from the given point to 4
boundaries (left, top, right, bottom). Shape (B, N, 4) or (N, 4)
预测的中心点到边界框四边的距离
Returns:
Tensor: Boxes with shape (N, 4) or (B, N, 4)
"""
x1 = points[..., 0] - distance[..., 0] # 中心点x坐标 - 左边距离 = 边界框左上角x坐标
y1 = points[..., 1] - distance[..., 1] # 中心点y坐标 - 上边距离 = 边界框左上角y坐标
x2 = points[..., 0] + distance[..., 2] # 中心点x坐标 - 右边距离 = 边界框右下角x坐标
y2 = points[..., 1] + distance[..., 3] # 中心点y坐标 - 下边距离 = 边界框右下角y坐标
bboxes = torch.stack([x1, y1, x2, y2], -1)
......
return bboxes
将 gt bboxes (x1, y1, x2, y2) 编码为 (top, bottom, left, right)的编码过程,
def bbox2distance(points: Tensor,
bbox: Tensor,
.......) -> Tensor:
"""Decode bounding box based on distances.
Args:
points (Tensor): Shape (n, 2) or (b, n, 2), [x, y]. 网格中心点坐标
bbox (Tensor): Shape (n, 4) or (b, n, 4), "xyxy" format 真实值Ground Truth的左上角和右下角坐标
......
Returns:
Tensor: Decoded distances.
"""
left = points[..., 0] - bbox[..., 0] # 中心点x坐标 - 边界框左上角x坐标 = 左边距离
top = points[..., 1] - bbox[..., 1] # 中心点y坐标 - 边界框左上角y坐标 = 上边距离
right = bbox[..., 2] - points[..., 0] # 边界框右下角x坐标 - 中心点x坐标 = 右边距离
bottom = bbox[..., 3] - points[..., 1] # 边界框右下角y坐标 - 中心点y坐标 = 右边距离
.....
return torch.stack([left, top, right, bottom], -1)
5、将展开后的预测结果、points(anchors)先验、Ground Truth等传入self.get_targets()准备进行正负样本分配
cls_reg_targets = self.get_targets(
flatten_cls_scores,
flatten_bboxes,
anchor_list,
valid_flag_list,
batch_gt_instances,
batch_img_metas,
batch_gt_instances_ignore=batch_gt_instances_ignore)
注意这里是整个batch的数据传入self.get_targets()函数的,而且anchors_list的维度还是,所以得进行一维展开,
def get_targets(self,
cls_scores: Tensor,
bbox_preds: Tensor,
anchor_list: List[List[Tensor]],
valid_flag_list: List[List[Tensor]],
batch_gt_instances: InstanceList,
batch_img_metas: List[dict],
batch_gt_instances_ignore: OptInstanceList = None,
unmap_outputs=True):
num_imgs = len(batch_img_metas)
assert len(anchor_list) == len(valid_flag_list) == num_imgs
# anchor number of multi levels
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
# concat all level anchors and flags to a single tensor
for i in range(num_imgs):
assert len(anchor_list[i]) == len(valid_flag_list[i])
anchor_list[i] = torch.cat(anchor_list[i])
valid_flag_list[i] = torch.cat(valid_flag_list[i])
........
对gt_ignore 处理一下
# compute targets for each image
if batch_gt_instances_ignore is None:
batch_gt_instances_ignore = [None] * num_imgs
关于目标检测中gt_ignore的简单理解:目标过小,过于模糊当做ignore属性处理,训练时,给样本-1类别(背景为0类别)。评测时候需要考虑ignore样本,输出不算错。在有的模型的正负样本分配过程中,ignore区域使用是在一张图片挑选完正样本的时候,剩下的负样本按理来说是正常的从中random抽取,但是对于和ignore区域交叉大于0.5的区域是不能作为负样本的,因为这些区域不是没有人的区域,所以说ignore区域是人,但是这个人的遮挡太多了,所以要ignore,所以对于图片上的人啊,led里面的人是不能作为ignore区域的,因为要抑制掉!!!
在self.get_targets()函数内部调用self._get_targets_single进行单张图片的正负样本分配
(all_anchors, all_labels, all_label_weights, all_bbox_targets,
all_assign_metrics, sampling_results_list) = multi_apply(
self._get_targets_single,
cls_scores.detach(),
bbox_preds.detach(),
anchor_list,
valid_flag_list,
batch_gt_instances,
batch_img_metas,
batch_gt_instances_ignore,
unmap_outputs=unmap_outputs)
6、在self._get_targets_single()函数内部,去掉超出图片范围的anchors,对模型的预测结果和anchors一起用抽象数据接口InstanceData封装,然后送入样本分配器进行正负样本的分配
这里应该是要处理数据增广流程中Pad流程中引入的padding了,这些padding区域的anchors也是无效的。
inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
img_meta['img_shape'][:2], # 这里获取图像的真实范围
self.train_cfg['allowed_border']) # 是否允许超出一定边界
if not inside_flags.any():
return (None, ) * 7
# assign gt and sample anchors
anchors = flat_anchors[inside_flags, :]
def anchor_inside_flags(flat_anchors: Tensor,
valid_flags: Tensor,
img_shape: Tuple[int],
allowed_border: int = 0) -> Tensor:
img_h, img_w = img_shape[:2]
if allowed_border >= 0:
if isinstance(flat_anchors, BaseBoxes):
inside_flags = valid_flags & \
flat_anchors.is_inside([img_h, img_w],
all_inside=True,
allowed_border=allowed_border)
# flat_anchors.is_inside()是BaseBoxes类中找出在图像范围内anchors的方法
else:
inside_flags = valid_flags & \
(flat_anchors[:, 0] >= -allowed_border) & \
(flat_anchors[:, 1] >= -allowed_border) & \
(flat_anchors[:, 2] < img_w + allowed_border) & \
(flat_anchors[:, 3] < img_h + allowed_border)
else:
inside_flags = valid_flags
return inside_flags
去除无效anchors后,对模型的预测结果和anchors一起用抽象数据接口InstanceData封装,然后送入样本分配器进行正负样本的分配。
pred_instances = InstanceData(
scores=cls_scores[inside_flags, :],
bboxes=bbox_preds[inside_flags, :],
priors=anchors)
assign_result = self.assigner.assign(pred_instances, gt_instances,
gt_instances_ignore)
关于抽象数据接口
MMEngine定义了数据基类BaseDataElement, 中存在两种类型的数据,一种是 data 类型,如标注框、框的标签、和实例掩码等;另一种是 metainfo 类型,包含数据的元信息以确保数据的完整性,如 img_shape, img_id 等数据所在图片的一些基本信息,方便可视化等情况下对数据进行恢复和使用。
InstanceData 在 BaseDataElement 的基础上,对 data 存储的数据做了限制,即要求存储在 data 中的数据的长度一致。比如在目标检测中, 假设一张图像中有 N 个目标(instance),可以将图像的所有边界框(bbox),类别(label)等存储在 InstanceData 中, InstanceData 的 bbox 和 label 的长度相同。 基于上述假定对 InstanceData进行了扩展,包括:
-
对 InstanceData 中 data 所存储的数据进行了长度校验
-
data 部分支持类字典访问和设置它的属性
-
支持基础索引,切片以及高级索引功能
-
支持具有相同的 key 但是不同 InstanceData 的拼接功能。 这些扩展功能除了支持基础的数据结构, 比如torch.tensor, numpy.dnarray, list, str, tuple, 也可以是自定义的数据结构,只要自定义数据结构实现了 __len__, __getitem__ and cat.
详情查阅MMEngine抽象数据接口文档,示例如下:
<InstanceData(
META INFORMATION
pad_shape: (800, 1216, 3)
img_shape: (800, 1196, 3)
DATA FIELDS
cls_scores: tensor([0.8000, 0.7000])
bbox_preds: tensor([[0.6576, 0.5435, 0.5253, 0.8273],
[0.4533, 0.6848, 0.7230, 0.9279]])
anchors: tensor([[0.6566, 0.1254, 0.5253, 0.8273],
[0.4533, 0.6848, 0.7230, 0.9279]])
) at 0x7f9f339f8ca0>
7、DynamicSoftLabelAssigner正负样本分配
RTMDet基于YOLOX的SimOTA进行了改进,提出了DynamicSoftLabelAssigner, 正负样本的分配主要由该类完成。
assigner=dict(type="DynamicSoftLabelAssigner", topk=13)
@TASK_UTILS.register_module()
class DynamicSoftLabelAssigner(BaseAssigner):
"""Computes matching between predictions and ground truth with dynamic soft
label assignment.
Args:
soft_center_radius (float): Radius of the soft center prior.
Defaults to 3.0.
topk (int): Select top-k predictions to calculate dynamic k
best matches for each gt. Defaults to 13.
iou_weight (float): The scale factor of iou cost. Defaults to 3.0.
iou_calculator (ConfigType): Config of overlaps Calculator.
Defaults to dict(type='BboxOverlaps2D').
"""
def __init__(
self,
soft_center_radius: float = 3.0,
topk: int = 13,
iou_weight: float = 3.0,
iou_calculator: ConfigType = dict(type='BboxOverlaps2D')
) -> None:
self.soft_center_radius = soft_center_radius
self.topk = topk
self.iou_weight = iou_weight
self.iou_calculator = TASK_UTILS.build(iou_calculator)
def assign(self,
pred_instances: InstanceData,
gt_instances: InstanceData,
gt_instances_ignore: Optional[InstanceData] = None,
**kwargs) -> AssignResult:
"""Assign gt to priors.
Args:
pred_instances (:obj:`InstanceData`): Instances of model
predictions. It includes ``priors``, and the priors can
be anchors or points, or the bboxes predicted by the
previous stage, has shape (n, 4). The bboxes predicted by
the current model or stage will be named ``bboxes``,
``labels``, and ``scores``, the same as the ``InstanceData``
in other places.
gt_instances (:obj:`InstanceData`): Ground truth of instance
annotations. It usually includes ``bboxes``, with shape (k, 4),
and ``labels``, with shape (k, ).
gt_instances_ignore (:obj:`InstanceData`, optional): Instances
to be ignored during training. It includes ``bboxes``
attribute data that is ignored during training and testing.
Defaults to None.
Returns:
obj:`AssignResult`: The assigned result.
"""
gt_bboxes = gt_instances.bboxes
gt_labels = gt_instances.labels
num_gt = gt_bboxes.size(0)
decoded_bboxes = pred_instances.bboxes
pred_scores = pred_instances.scores
priors = pred_instances.priors
num_bboxes = decoded_bboxes.size(0)
# assign 0 by default
# 每个预测的bbox只允许匹配一个Ground Truth
assigned_gt_inds = decoded_bboxes.new_full((num_bboxes, ),
0,
dtype=torch.long)
# 加入没有Ground Truth或者预测结果为空,则返回空的分配结果
if num_gt == 0 or num_bboxes == 0:
# No ground truth or boxes, return empty assignment
max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
if num_gt == 0:
# No truth, assign everything to background
assigned_gt_inds[:] = 0
assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
-1,
dtype=torch.long)
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
# 找出中心点在Ground Truth内的priors
prior_center = priors[:, :2] # (n, 2)
if isinstance(gt_bboxes, BaseBoxes):
is_in_gts = gt_bboxes.find_inside_points(prior_center)
else:
# Tensor boxes will be treated as horizontal boxes by defaults
# prior_center[:, None].shape: (num_priors, 1, 2)
# gt_bboxes[:, :2].shape: (num_gt,2)
# 两者通过广播机制实现相减
lt_ = prior_center[:, None] - gt_bboxes[:, :2] # 中心点到每个真值框左边和上边的距离,维度为(num_priors, num_gt, 2)
rb_ = gt_bboxes[:, 2:] - prior_center[:, None] # 中心点到每个真值框右边和下边的距离,维度为(num_priors, num_gt, 2)
deltas = torch.cat([lt_, rb_], dim=-1)
is_in_gts = deltas.min(dim=-1).values > 0 # 中心点到每个真值框四边的距离,维度为(num_priors, num_gt, 4),只有四边距离的最小值都大于0,才能说该prior在该真值框内,最后得到的is_in_gts的维度为(num_priors,num_gt)
valid_mask = is_in_gts.sum(dim=1) > 0 # 可能存在真值框重叠的情况,即一个prior在多个真值框内,所以对is_in_gts的第一个维度求和大于0的中心点在Ground Truth内的priors
# 取得中心点在Ground Truth内的有效预测结果
valid_decoded_bbox = decoded_bboxes[valid_mask]
valid_pred_scores = pred_scores[valid_mask]
num_valid = valid_decoded_bbox.size(0)
# 如果所有预测结果的中心点都不在Ground Truth内(是指没有Ground Truth或预测的bboxes)返回空的分配结果
if num_valid == 0:
# No ground truth or boxes, return empty assignment
max_overlaps = decoded_bboxes.new_zeros((num_bboxes, ))
assigned_labels = decoded_bboxes.new_full((num_bboxes, ),
-1,
dtype=torch.long)
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
if hasattr(gt_instances, 'masks'):
gt_center = center_of_mass(gt_instances.masks, eps=EPS) # 实例分割的?
elif isinstance(gt_bboxes, BaseBoxes):
gt_center = gt_bboxes.centers
else:
# Tensor boxes will be treated as horizontal boxes by defaults
gt_center = (gt_bboxes[:, :2] + gt_bboxes[:, 2:]) / 2.0 # (左上角坐标 + 右下角坐标)/ 2 = 中心点坐标
valid_prior = priors[valid_mask] # 过滤无效的先验,假设有效先验的数量为num_val,则valid_prior维度为(num_val,4)
strides = valid_prior[:, 2] # 进而获取有效先验对应的strides, 维度为(num_val,1)
distance = (valid_prior[:, None, :2] - gt_center[None, :, :]
).pow(2).sum(-1).sqrt() / strides[:, None] # 有效先验中心点到Ground Truth中心点的距离,维度应该是(num_val, num_gt)
soft_center_prior = torch.pow(10, distance - self.soft_center_radius)
pairwise_ious = self.iou_calculator(valid_decoded_bbox, gt_bboxes) # 维度应该是(num_val, num_gt)
iou_cost = -torch.log(pairwise_ious + EPS) * self.iou_weight # (num_val, num_gt)
# pred_scores.shape[-1]是目标类别总数
# F.one_hot(gt_labels.to(torch.int64), pred_scores.shape[-1])得到的维度应该是(num_gt, num_class)
gt_onehot_label = (
F.one_hot(gt_labels.to(torch.int64),
pred_scores.shape[-1]).float().unsqueeze(0).repeat(
num_valid, 1, 1)) # 重复num_val次是因为每个prior需要和每个Ground Truth计算损失,此时维度为(num_val, num_gt, num_class)
valid_pred_scores = valid_pred_scores.unsqueeze(1).repeat(1, num_gt, 1) # 维度为(num_val, num_gt, num_class)
soft_label = gt_onehot_label * pairwise_ious[..., None] # 预测结果和真实值之间的IoU作为软标签$Y_{soft}$
scale_factor = soft_label - valid_pred_scores.sigmoid() # 维度为(num_val, num_gt, num_class) 对应分类代价函数的$(Y_{soft} - P)$
soft_cls_cost = F.binary_cross_entropy_with_logits(
valid_pred_scores, soft_label,
reduction='none') * scale_factor.abs().pow(2.0) # reduction='none'表示计算交叉熵后不计算平均值,而是保持维度不变
soft_cls_cost = soft_cls_cost.sum(dim=-1) # (num_val, num_gt)
cost_matrix = soft_cls_cost + iou_cost + soft_center_prior # (num_val, num_gt) 代价矩阵,每一行代表该预测结果相对于每个gt的分配代价
matched_pred_ious, matched_gt_inds = self.dynamic_k_matching(
cost_matrix, pairwise_ious, num_gt, valid_mask)
# convert to AssignResult format
assigned_gt_inds[valid_mask] = matched_gt_inds + 1
assigned_labels = assigned_gt_inds.new_full((num_bboxes, ), -1)
assigned_labels[valid_mask] = gt_labels[matched_gt_inds].long()
max_overlaps = assigned_gt_inds.new_full((num_bboxes, ),
-INF,
dtype=torch.float32)
max_overlaps[valid_mask] = matched_pred_ious
return AssignResult(
num_gt, assigned_gt_inds, max_overlaps, labels=assigned_labels)
def dynamic_k_matching(self, cost: Tensor, pairwise_ious: Tensor,
num_gt: int,
valid_mask: Tensor) -> Tuple[Tensor, Tensor]:
"""Use IoU and matching cost to calculate the dynamic top-k positive
targets. Same as SimOTA.
Args:
cost (Tensor): Cost matrix. (num_val, num_gt)
pairwise_ious (Tensor): Pairwise iou matrix. (num_val, num_gt)
num_gt (int): Number of gt.
valid_mask (Tensor): Mask for valid bboxes. (num_priors,) 其中有限先验为True,无效先验为False
Returns:
tuple: matched ious and gt indexes.
"""
# 匹配矩阵初始化为 0
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
# select candidate topk ious for dynamic-k calculation
# self.topk = 13, pairwise_ious.size(0) = num_val
candidate_topk = min(self.topk, pairwise_ious.size(0))
topk_ious, _ = torch.topk(pairwise_ious, candidate_topk, dim=0) # 沿着维度0选取topk,即为每个gt选取前topk个iou最大的bbox, 维度为(topk, num_gt)
# calculate dynamic k for each gt
# 计算每一个 gt 与所有 bboxes 前 13 大的 iou的和取整后作为这个 gt 的 样本数目 , 最少为 1 个, 记为 dynamic_ks, 维度为(num_gt,)
dynamic_ks = torch.clamp(topk_ious.sum(0).int(), min=1)
# 对于每一个 gt , 将其 cost_matrix 矩阵前 `dynamic_ks 小的位置作为该 gt 的正样本
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(
cost[:, gt_idx], k=dynamic_ks[gt_idx], largest=False)
matching_matrix[:, gt_idx][pos_idx] = 1
del topk_ious, dynamic_ks, pos_idx # 删除中间变量
# 对于某一个 bbox, 如果被匹配到多个 gt 就将与这些 gts 的 cost_marix 中最小的那个作为其 label
prior_match_gt_mask = matching_matrix.sum(1) > 1 # 先验匹配gt掩码,判断维度1上的和是否大于1,找出匹配上多个gt的预测点
if prior_match_gt_mask.sum() > 0:
cost_min, cost_argmin = torch.min(
cost[prior_match_gt_mask, :], dim=1)
matching_matrix[prior_match_gt_mask, :] *= 0
matching_matrix[prior_match_gt_mask, cost_argmin] = 1
# get foreground mask inside box and center prior
fg_mask_inboxes = matching_matrix.sum(1) > 0 # 前景掩码
# 更新前景掩码,在前面中心先验的前提下进一步筛选正样本
# 注意这个索引方式,valid_mask是一个bool类型tensor,以自己为索引会返回所有为True的位置
# 也就是说 valid_mask的维度本来是(num_priors,),以自己为索引会返回所有为True的位置后维度自然就变成了(num_val,)
valid_mask[valid_mask.clone()] = fg_mask_inboxes
# 该候选框匹配到哪个 gt bbox
matched_gt_inds = matching_matrix[fg_mask_inboxes, :].argmax(1)
# 提取对应的预测点和gt bbox 的 iou
matched_pred_ious = (matching_matrix *
pairwise_ious).sum(1)[fg_mask_inboxes]
return matched_pred_ious, matched_gt_inds
样本分配结果采用AssignResult类封装
class AssignResult(util_mixins.NiceRepr):
def __init__(self, num_gts: int, gt_inds: Tensor, max_overlaps: Tensor,
labels: Tensor) -> None:
self.num_gts = num_gts
self.gt_inds = gt_inds
self.max_overlaps = max_overlaps
self.labels = labels
# Interface for possible user-defined properties
self._extra_properties = {}
8、正负样本采样
在目标检测流程中,一眼分配完正负样本之后还会进行一个采样的过程,目的是为了让正负样本更加均衡。RTMDet采用的是伪采样器,即实际上不进行采样,直接返回正负样本的索引
class PseudoSampler(BaseSampler):
"""A pseudo sampler that does not do sampling actually."""
def __init__(self, **kwargs):
pass
def _sample_pos(self, **kwargs):
"""Sample positive samples."""
raise NotImplementedError
def _sample_neg(self, **kwargs):
"""Sample negative samples."""
raise NotImplementedError
def sample(self, assign_result: AssignResult, pred_instances: InstanceData,
gt_instances: InstanceData, *args, **kwargs):
"""Directly returns the positive and negative indices of samples.
Args:
assign_result (:obj:`AssignResult`): Bbox assigning results.
pred_instances (:obj:`InstanceData`): Instances of model
predictions. It includes ``priors``, and the priors can
be anchors, points, or bboxes predicted by the model,
shape(n, 4).
gt_instances (:obj:`InstanceData`): Ground truth of instance
annotations. It usually includes ``bboxes`` and ``labels``
attributes.
Returns:
:obj:`SamplingResult`: sampler results
"""
gt_bboxes = gt_instances.bboxes
priors = pred_instances.priors
# torch.nonezero()的作用就是找到tensor中所有不为0的索引。
pos_inds = torch.nonzero( # 正样本索引
assign_result.gt_inds > 0, as_tuple=False).squeeze(-1).unique()
neg_inds = torch.nonzero( # 负样本索引
assign_result.gt_inds == 0, as_tuple=False).squeeze(-1).unique()
gt_flags = priors.new_zeros(priors.shape[0], dtype=torch.uint8) # 这是干啥的?
sampling_result = SamplingResult(
pos_inds=pos_inds,
neg_inds=neg_inds,
priors=priors,
gt_bboxes=gt_bboxes,
assign_result=assign_result,
gt_flags=gt_flags,
avg_factor_with_neg=False)
return sampling_result
抽样结果采用SamplingResult封装,比较重要是下面添加注释的那几项,预测结果中哪些是正样本、哪些是负样本,每个正样本负责预测哪个ground truth,对应的类别是什么
class SamplingResult(util_mixins.NiceRepr):
def __init__(self,
pos_inds: Tensor,
neg_inds: Tensor,
priors: Tensor,
gt_bboxes: Tensor,
assign_result: AssignResult,
gt_flags: Tensor,
avg_factor_with_neg: bool = True) -> None:
self.pos_inds = pos_inds
self.neg_inds = neg_inds
self.num_pos = max(pos_inds.numel(), 1)
self.num_neg = max(neg_inds.numel(), 1)
self.avg_factor_with_neg = avg_factor_with_neg
self.avg_factor = self.num_pos + self.num_neg \
if avg_factor_with_neg else self.num_pos
self.pos_priors = priors[pos_inds] # 正样本
self.neg_priors = priors[neg_inds] # 负样本
self.pos_is_gt = gt_flags[pos_inds]
self.num_gts = gt_bboxes.shape[0]
self.pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1 # 正样本负责预测ground truth的索引
self.pos_gt_labels = assign_result.labels[pos_inds] # 该正样本应该是哪个类别
box_dim = gt_bboxes.box_dim if isinstance(gt_bboxes, BaseBoxes) else 4
if gt_bboxes.numel() == 0:
# hack for index error case
assert self.pos_assigned_gt_inds.numel() == 0
self.pos_gt_bboxes = gt_bboxes.view(-1, box_dim)
else:
if len(gt_bboxes.shape) < 2:
gt_bboxes = gt_bboxes.view(-1, box_dim)
self.pos_gt_bboxes = gt_bboxes[self.pos_assigned_gt_inds.long()] # 正样本负责预测ground truth的bbox
9、根据抽样结果构建用于计算loss的target
回顾一下,我们送入正负样本分配器和抽样器的是在真实图片范围内的anchors,
anchors = flat_anchors[inside_flags, :]
因此需要先构建anchors对应的target,包括bbox_terget(每个anchor对应的目标bbox,正样本对应真实的bbox,负样本对应0)、目标标签labels(同样正样本对应真值的标签,负样本对应0)、标签类别的权重、用于计算QualityFocalLoss的assign_metrics,构建过程如下:
num_valid_anchors = anchors.shape[0] #
bbox_targets = torch.zeros_like(anchors) # 初始化每个有效anchor对应的边界框目标为0
labels = anchors.new_full((num_valid_anchors, ), # 初始化每个有效anchor对应的标签目标为目标类别数
self.num_classes,
dtype=torch.long)
label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float) # 标签权重初始化为0
assign_metrics = anchors.new_zeros( # 分配指标初始化为0,指示分配质量好不好,因为RTMDet采用的分类损失函数为'QualityFocalLoss',这是用来计算分类损失的
num_valid_anchors, dtype=torch.float)
pos_inds = sampling_result.pos_inds # 从抽样结果中获取正样本索引
neg_inds = sampling_result.neg_inds # 从抽样结果中获取负样本索引
if len(pos_inds) > 0:
# point-based
pos_bbox_targets = sampling_result.pos_gt_bboxes
bbox_targets[pos_inds, :] = pos_bbox_targets # 更新负责预测正样本的bbox
labels[pos_inds] = sampling_result.pos_gt_labels # 更新负责预测的正样本的类别标签
if self.train_cfg['pos_weight'] <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = self.train_cfg['pos_weight']
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
# 采用iou评估分配质量
class_assigned_gt_inds = torch.unique(
sampling_result.pos_assigned_gt_inds)
for gt_inds in class_assigned_gt_inds:
gt_class_inds = pos_inds[sampling_result.pos_assigned_gt_inds ==
gt_inds]
assign_metrics[gt_class_inds] = assign_result.max_overlaps[
gt_class_inds]
前面把数据增广过程中Pad加上的padding去掉了,只处理在真实图片范围内的anchors,现在把维度还原回去
if unmap_outputs:
num_total_anchors = flat_anchors.size(0)
anchors = unmap(anchors, num_total_anchors, inside_flags)
labels = unmap(
labels, num_total_anchors, inside_flags, fill=self.num_classes)
label_weights = unmap(label_weights, num_total_anchors,
inside_flags)
bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
assign_metrics = unmap(assign_metrics, num_total_anchors,
inside_flags)
返回结果
return (anchors, labels, label_weights, bbox_targets, assign_metrics,
sampling_result)
接受返回的结果
(all_anchors, all_labels, all_label_weights, all_bbox_targets,
all_assign_metrics, sampling_results_list) = multi_apply(
self._get_targets_single,
cls_scores.detach(),
bbox_preds.detach(),
anchor_list,
valid_flag_list,
batch_gt_instances,
batch_img_metas,
batch_gt_instances_ignore,
unmap_outputs=unmap_outputs)
# no valid anchors
if any([labels is None for labels in all_labels]):
return None
上面把每张图片所有尺度的预测串联合在一起做正负样本的分配、采样等工作,现在再把结果拆分回不同的尺度
前面记录每个尺度的特征图有多少anchors
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
拆分结果并返回
anchors_list = images_to_levels(all_anchors, num_level_anchors)
labels_list = images_to_levels(all_labels, num_level_anchors)
label_weights_list = images_to_levels(all_label_weights,
num_level_anchors)
bbox_targets_list = images_to_levels(all_bbox_targets,
num_level_anchors)
assign_metrics_list = images_to_levels(all_assign_metrics,
num_level_anchors)
return (anchors_list, labels_list, label_weights_list,
bbox_targets_list, assign_metrics_list, sampling_results_list)
至此,完成了targets的构建,维度与模型的预测输出一致,
10、计算loss
上一步构建的targets如下:
(anchor_list, labels_list, label_weights_list, bbox_targets_list,
assign_metrics_list, sampling_results_list) = cls_reg_targets
接着按尺度计算loss
losses_cls, losses_bbox,\
cls_avg_factors, bbox_avg_factors = multi_apply(
self.loss_by_feat_single, # 按尺度计算loss
cls_scores, # 分类分支的输出
decoded_bboxes, # 回归分支的输出
# 以下是构建的targets
labels_list,
label_weights_list,
bbox_targets_list,
assign_metrics_list,
self.prior_generator.strides)
def loss_by_feat_single(self, cls_score: Tensor, bbox_pred: Tensor,
labels: Tensor, label_weights: Tensor,
bbox_targets: Tensor, assign_metrics: Tensor,
stride: List[int]):
"""Compute loss of a single scale level.
Args:
cls_score (Tensor): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W).
bbox_pred (Tensor): Decoded bboxes for each scale
level with shape (N, num_anchors * 4, H, W).
labels (Tensor): Labels of each anchors with shape
(N, num_total_anchors).
label_weights (Tensor): Label weights of each anchor with shape
(N, num_total_anchors).
bbox_targets (Tensor): BBox regression targets of each anchor with
shape (N, num_total_anchors, 4).
assign_metrics (Tensor): Assign metrics with shape
(N, num_total_anchors).
stride (List[int]): Downsample stride of the feature map.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
assert stride[0] == stride[1], 'h stride is not equal to w stride!'
# 一维展开
cls_score = cls_score.permute(0, 2, 3, 1).reshape(
-1, self.cls_out_channels).contiguous()
bbox_pred = bbox_pred.reshape(-1, 4)
bbox_targets = bbox_targets.reshape(-1, 4)
labels = labels.reshape(-1)
assign_metrics = assign_metrics.reshape(-1)
label_weights = label_weights.reshape(-1)
targets = (labels, assign_metrics)
# 计算分类损失
loss_cls = self.loss_cls(
cls_score, targets, label_weights, avg_factor=1.0)
# 计算回归损失
# FG cat_id: [0, num_classes -1], BG cat_id: num_classes 这是前景类别id的范围和北京类别的id,比如在coco数据集中共有80个类别,那么前景的类别为[0,79],背景的类别为80
bg_class_ind = self.num_classes
pos_inds = ((labels >= 0)
& (labels < bg_class_ind)).nonzero().squeeze(1) # 获取正样本的索引
if len(pos_inds) > 0:
pos_bbox_targets = bbox_targets[pos_inds]
pos_bbox_pred = bbox_pred[pos_inds]
pos_decode_bbox_pred = pos_bbox_pred
pos_decode_bbox_targets = pos_bbox_targets
# regression loss
pos_bbox_weight = assign_metrics[pos_inds]
loss_bbox = self.loss_bbox(
pos_decode_bbox_pred,
pos_decode_bbox_targets,
weight=pos_bbox_weight,
avg_factor=1.0)
else:
loss_bbox = bbox_pred.sum() * 0
pos_bbox_weight = bbox_targets.new_tensor(0.)
return loss_cls, loss_bbox, assign_metrics.sum(), pos_bbox_weight.sum()
计算分类损失QualityFocalLoss
loss_cls=dict(type="QualityFocalLoss", use_sigmoid=True, beta=2.0, loss_weight=1.0),
@MODELS.register_module()
class QualityFocalLoss(nn.Module):
r"""Quality Focal Loss (QFL) is a variant of `Generalized Focal Loss:
Learning Qualified and Distributed Bounding Boxes for Dense Object
Detection <https://arxiv.org/abs/2006.04388>`_.
Args:
use_sigmoid (bool): Whether sigmoid operation is conducted in QFL.
Defaults to True.
beta (float): The beta parameter for calculating the modulating factor.
Defaults to 2.0.
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Loss weight of current loss.
activated (bool, optional): Whether the input is activated.
If True, it means the input has been activated and can be
treated as probabilities. Else, it should be treated as logits.
Defaults to False.
"""
def __init__(self,
use_sigmoid=True,
beta=2.0,
reduction='mean',
loss_weight=1.0,
activated=False):
super(QualityFocalLoss, self).__init__()
assert use_sigmoid is True, 'Only sigmoid in QFL supported now.'
self.use_sigmoid = use_sigmoid
self.beta = beta
self.reduction = reduction
self.loss_weight = loss_weight
self.activated = activated
def forward(self,
pred,
target,
weight=None,
avg_factor=None,
reduction_override=None):
"""Forward function.
Args:
pred (torch.Tensor): Predicted joint representation of
classification and quality (IoU) estimation with shape (N, C),
C is the number of classes.
target (Union(tuple([torch.Tensor]),Torch.Tensor)): The type is
tuple, it should be included Target category label with
shape (N,) and target quality label with shape (N,).The type
is torch.Tensor, the target should be one-hot form with
soft weights.
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if self.use_sigmoid:
if self.activated:
calculate_loss_func = quality_focal_loss_with_prob
else:
calculate_loss_func = quality_focal_loss
if isinstance(target, torch.Tensor):
# the target shape with (N,C) or (N,C,...), which means
# the target is one-hot form with soft weights.
calculate_loss_func = partial(
quality_focal_loss_tensor_target, activated=self.activated)
loss_cls = self.loss_weight * calculate_loss_func(
pred,
target,
weight,
beta=self.beta,
reduction=reduction,
avg_factor=avg_factor)
else:
raise NotImplementedError
return loss_cls
@weighted_loss
def quality_focal_loss(pred, target, beta=2.0):
r"""Quality Focal Loss (QFL) is from `Generalized Focal Loss: Learning
Qualified and Distributed Bounding Boxes for Dense Object Detection
<https://arxiv.org/abs/2006.04388>`_.
Args:
pred (torch.Tensor): Predicted joint representation of classification
and quality (IoU) estimation with shape (N, C), C is the number of
classes.
target (tuple([torch.Tensor])): Target category label with shape (N,)
and target quality label with shape (N,).
beta (float): The beta parameter for calculating the modulating factor.
Defaults to 2.0.
Returns:
torch.Tensor: Loss tensor with shape (N,).
"""
assert len(target) == 2, """target for QFL must be a tuple of two elements,
including category label and quality label, respectively"""
# label denotes the category id, score denotes the quality score
label, score = target
# negatives are supervised by 0 quality score
pred_sigmoid = pred.sigmoid()
scale_factor = pred_sigmoid
zerolabel = scale_factor.new_zeros(pred.shape)
loss = F.binary_cross_entropy_with_logits(
pred, zerolabel, reduction='none') * scale_factor.pow(beta)
# FG cat_id: [0, num_classes -1], BG cat_id: num_classes
bg_class_ind = pred.size(1)
pos = ((label >= 0) & (label < bg_class_ind)).nonzero().squeeze(1)
pos_label = label[pos].long()
# positives are supervised by bbox quality (IoU) score
scale_factor = score[pos] - pred_sigmoid[pos, pos_label]
loss[pos, pos_label] = F.binary_cross_entropy_with_logits(
pred[pos, pos_label], score[pos],
reduction='none') * scale_factor.abs().pow(beta)
loss = loss.sum(dim=1, keepdim=False)
return loss
计算回归损失GIoULoss
loss_bbox=dict(type="GIoULoss", loss_weight=2.0),
@MODELS.register_module()
class GIoULoss(nn.Module):
r"""`Generalized Intersection over Union: A Metric and A Loss for Bounding
Box Regression <https://arxiv.org/abs/1902.09630>`_.
Args:
eps (float): Epsilon to avoid log(0).
reduction (str): Options are "none", "mean" and "sum".
loss_weight (float): Weight of loss.
"""
def __init__(self,
eps: float = 1e-6,
reduction: str = 'mean',
loss_weight: float = 1.0) -> None:
super().__init__()
self.eps = eps
self.reduction = reduction
self.loss_weight = loss_weight
def forward(self,
pred: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
avg_factor: Optional[int] = None,
reduction_override: Optional[str] = None,
**kwargs) -> Tensor:
"""Forward function.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): The learning target of the prediction,
shape (n, 4).
weight (Optional[Tensor], optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (Optional[int], optional): Average factor that is used
to average the loss. Defaults to None.
reduction_override (Optional[str], optional): The reduction method
used to override the original reduction method of the loss.
Defaults to None. Options are "none", "mean" and "sum".
Returns:
Tensor: Loss tensor.
"""
if weight is not None and not torch.any(weight > 0):
if pred.dim() == weight.dim() + 1:
weight = weight.unsqueeze(1)
return (pred * weight).sum() # 0
assert reduction_override in (None, 'none', 'mean', 'sum')
reduction = (
reduction_override if reduction_override else self.reduction)
if weight is not None and weight.dim() > 1:
# TODO: remove this in the future
# reduce the weight of shape (n, 4) to (n,) to match the
# giou_loss of shape (n,)
assert weight.shape == pred.shape
weight = weight.mean(-1)
loss = self.loss_weight * giou_loss(
pred,
target,
weight,
eps=self.eps,
reduction=reduction,
avg_factor=avg_factor,
**kwargs)
return loss
@weighted_loss
def giou_loss(pred: Tensor, target: Tensor, eps: float = 1e-7) -> Tensor:
r"""`Generalized Intersection over Union: A Metric and A Loss for Bounding
Box Regression <https://arxiv.org/abs/1902.09630>`_.
Args:
pred (Tensor): Predicted bboxes of format (x1, y1, x2, y2),
shape (n, 4).
target (Tensor): Corresponding gt bboxes, shape (n, 4).
eps (float): Epsilon to avoid log(0).
Return:
Tensor: Loss tensor.
"""
gious = bbox_overlaps(pred, target, mode='giou', is_aligned=True, eps=eps)
loss = 1 - gious
return loss
def bbox_overlaps(bboxes1, bboxes2, mode='iou', is_aligned=False, eps=1e-6):
"""Calculate overlap between two set of bboxes.
FP16 Contributed by https://github.com/open-mmlab/mmdetection/pull/4889
Note:
Assume bboxes1 is M x 4, bboxes2 is N x 4, when mode is 'iou',
there are some new generated variable when calculating IOU
using bbox_overlaps function:
1) is_aligned is False
area1: M x 1
area2: N x 1
lt: M x N x 2
rb: M x N x 2
wh: M x N x 2
overlap: M x N x 1
union: M x N x 1
ious: M x N x 1
Total memory:
S = (9 x N x M + N + M) * 4 Byte,
When using FP16, we can reduce:
R = (9 x N x M + N + M) * 4 / 2 Byte
R large than (N + M) * 4 * 2 is always true when N and M >= 1.
Obviously, N + M <= N * M < 3 * N * M, when N >=2 and M >=2,
N + 1 < 3 * N, when N or M is 1.
Given M = 40 (ground truth), N = 400000 (three anchor boxes
in per grid, FPN, R-CNNs),
R = 275 MB (one times)
A special case (dense detection), M = 512 (ground truth),
R = 3516 MB = 3.43 GB
When the batch size is B, reduce:
B x R
Therefore, CUDA memory runs out frequently.
Experiments on GeForce RTX 2080Ti (11019 MiB):
| dtype | M | N | Use | Real | Ideal |
|:----:|:----:|:----:|:----:|:----:|:----:|
| FP32 | 512 | 400000 | 8020 MiB | -- | -- |
| FP16 | 512 | 400000 | 4504 MiB | 3516 MiB | 3516 MiB |
| FP32 | 40 | 400000 | 1540 MiB | -- | -- |
| FP16 | 40 | 400000 | 1264 MiB | 276MiB | 275 MiB |
2) is_aligned is True
area1: N x 1
area2: N x 1
lt: N x 2
rb: N x 2
wh: N x 2
overlap: N x 1
union: N x 1
ious: N x 1
Total memory:
S = 11 x N * 4 Byte
When using FP16, we can reduce:
R = 11 x N * 4 / 2 Byte
So do the 'giou' (large than 'iou').
Time-wise, FP16 is generally faster than FP32.
When gpu_assign_thr is not -1, it takes more time on cpu
but not reduce memory.
There, we can reduce half the memory and keep the speed.
If ``is_aligned`` is ``False``, then calculate the overlaps between each
bbox of bboxes1 and bboxes2, otherwise the overlaps between each aligned
pair of bboxes1 and bboxes2.
Args:
bboxes1 (Tensor): shape (B, m, 4) in <x1, y1, x2, y2> format or empty.
bboxes2 (Tensor): shape (B, n, 4) in <x1, y1, x2, y2> format or empty.
B indicates the batch dim, in shape (B1, B2, ..., Bn).
If ``is_aligned`` is ``True``, then m and n must be equal.
mode (str): "iou" (intersection over union), "iof" (intersection over
foreground) or "giou" (generalized intersection over union).
Default "iou".
is_aligned (bool, optional): If True, then m and n must be equal.
Default False.
eps (float, optional): A value added to the denominator for numerical
stability. Default 1e-6.
Returns:
Tensor: shape (m, n) if ``is_aligned`` is False else shape (m,)
Example:
>>> bboxes1 = torch.FloatTensor([
>>> [0, 0, 10, 10],
>>> [10, 10, 20, 20],
>>> [32, 32, 38, 42],
>>> ])
>>> bboxes2 = torch.FloatTensor([
>>> [0, 0, 10, 20],
>>> [0, 10, 10, 19],
>>> [10, 10, 20, 20],
>>> ])
>>> overlaps = bbox_overlaps(bboxes1, bboxes2)
>>> assert overlaps.shape == (3, 3)
>>> overlaps = bbox_overlaps(bboxes1, bboxes2, is_aligned=True)
>>> assert overlaps.shape == (3, )
Example:
>>> empty = torch.empty(0, 4)
>>> nonempty = torch.FloatTensor([[0, 0, 10, 9]])
>>> assert tuple(bbox_overlaps(empty, nonempty).shape) == (0, 1)
>>> assert tuple(bbox_overlaps(nonempty, empty).shape) == (1, 0)
>>> assert tuple(bbox_overlaps(empty, empty).shape) == (0, 0)
"""
assert mode in ['iou', 'iof', 'giou'], f'Unsupported mode {mode}'
# Either the boxes are empty or the length of boxes' last dimension is 4
assert (bboxes1.size(-1) == 4 or bboxes1.size(0) == 0)
assert (bboxes2.size(-1) == 4 or bboxes2.size(0) == 0)
# Batch dim must be the same
# Batch dim: (B1, B2, ... Bn)
assert bboxes1.shape[:-2] == bboxes2.shape[:-2]
batch_shape = bboxes1.shape[:-2]
rows = bboxes1.size(-2)
cols = bboxes2.size(-2)
if is_aligned:
assert rows == cols
if rows * cols == 0:
if is_aligned:
return bboxes1.new(batch_shape + (rows, ))
else:
return bboxes1.new(batch_shape + (rows, cols))
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (
bboxes1[..., 3] - bboxes1[..., 1])
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (
bboxes2[..., 3] - bboxes2[..., 1])
if is_aligned:
lt = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [B, rows, 2]
rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [B, rows, 2]
wh = fp16_clamp(rb - lt, min=0)
overlap = wh[..., 0] * wh[..., 1]
if mode in ['iou', 'giou']:
union = area1 + area2 - overlap
else:
union = area1
if mode == 'giou':
enclosed_lt = torch.min(bboxes1[..., :2], bboxes2[..., :2])
enclosed_rb = torch.max(bboxes1[..., 2:], bboxes2[..., 2:])
else:
lt = torch.max(bboxes1[..., :, None, :2],
bboxes2[..., None, :, :2]) # [B, rows, cols, 2]
rb = torch.min(bboxes1[..., :, None, 2:],
bboxes2[..., None, :, 2:]) # [B, rows, cols, 2]
wh = fp16_clamp(rb - lt, min=0)
overlap = wh[..., 0] * wh[..., 1]
if mode in ['iou', 'giou']:
union = area1[..., None] + area2[..., None, :] - overlap
else:
union = area1[..., None]
if mode == 'giou':
enclosed_lt = torch.min(bboxes1[..., :, None, :2],
bboxes2[..., None, :, :2])
enclosed_rb = torch.max(bboxes1[..., :, None, 2:],
bboxes2[..., None, :, 2:])
eps = union.new_tensor([eps])
union = torch.max(union, eps)
ious = overlap / union
if mode in ['iou', 'iof']:
return ious
# calculate gious
enclose_wh = fp16_clamp(enclosed_rb - enclosed_lt, min=0)
enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
enclose_area = torch.max(enclose_area, eps)
gious = ious - (enclose_area - union) / enclose_area
return gious
对不同尺度的分类损失和回归损失取均值
cls_avg_factor = reduce_mean(sum(cls_avg_factors)).clamp_(min=1).item() # 不同尺度的assign_metrics.sum()的均值
losses_cls = list(map(lambda x: x / cls_avg_factor, losses_cls)) # 每个尺度的losses_cls都除以cls_avg_factor
bbox_avg_factor = reduce_mean( # 同上
sum(bbox_avg_factors)).clamp_(min=1).item()
losses_bbox = list(map(lambda x: x / bbox_avg_factor, losses_bbox))
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
loss字典最终在BaseModel的def train_step()函数中被处理并传给优化器封装器进行模型参数的更新
def train_step(self, data: Union[dict, tuple, list],
optim_wrapper: OptimWrapper) -> Dict[str, torch.Tensor]:
# Enable automatic mixed precision training context.
with optim_wrapper.optim_context(self):
data = self.data_preprocessor(data, True)
losses = self._run_forward(data, mode='loss') # type: ignore
parsed_losses, log_vars = self.parse_losses(losses) # type: ignore # 大概是对分类损失和回归损失进行加权求和
optim_wrapper.update_params(parsed_losses)
return log_vars
-
- RTMDetSepBNHead的网络结构
- 1、RTMDetSepBNHead的输出
- 2、获得points先验
- 3、将分类分支的预测结果展成以为并将同一张图片的预测结果串联起来
- 4、将回归分支预测的中心点到四边的距离解码成bbox并将同一张图片的预测结果串联起来
- 5、将展开后的预测结果、points(anchors)先验、Ground Truth等传入self.get_targets()准备进行正负样本分配
- 6、在self._get_targets_single()函数内部,去掉超出图片范围的anchors,对模型的预测结果和anchors一起用抽象数据接口InstanceData封装,然后送入样本分配器进行正负样本的分配
- 7、DynamicSoftLabelAssigner正负样本分配
- 8、正负样本采样
- 9、根据抽样结果构建用于计算loss的target
- 10、计算loss