注意力机制是由于人类无法同时处理接收到的海量视觉信息而选择性地重点关注或忽略部分信息的信息处理方式。空间注意力是最直接的注意力机制,空间注意力最自然的实现应该就是计算出一个空间注意力权重图然后和特征图相乘,即
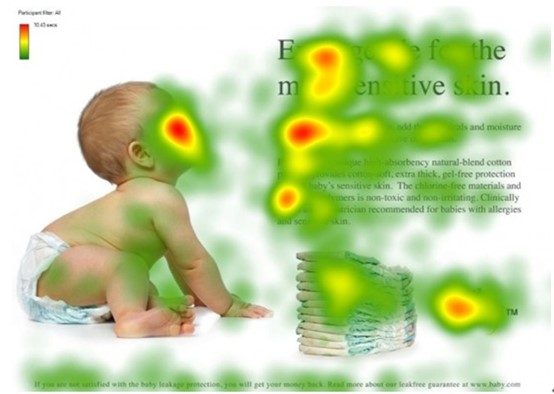
图片来自博客:热力图与原始图像融合
原始空间注意力
此种实现的空间注意力机制代表是:CBAM
论文地址:Cbam: Convolutional block attention module
代码地址:
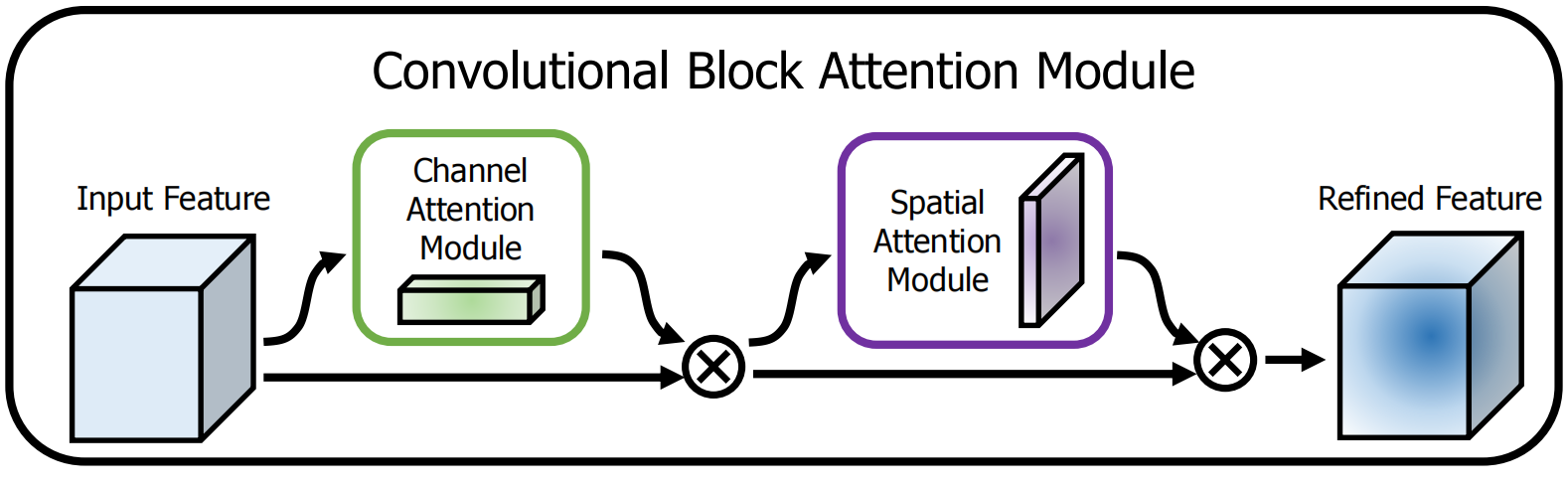
CBAM模块包含一个通道注意力模块和一个空间注意力模块,如下图所示,
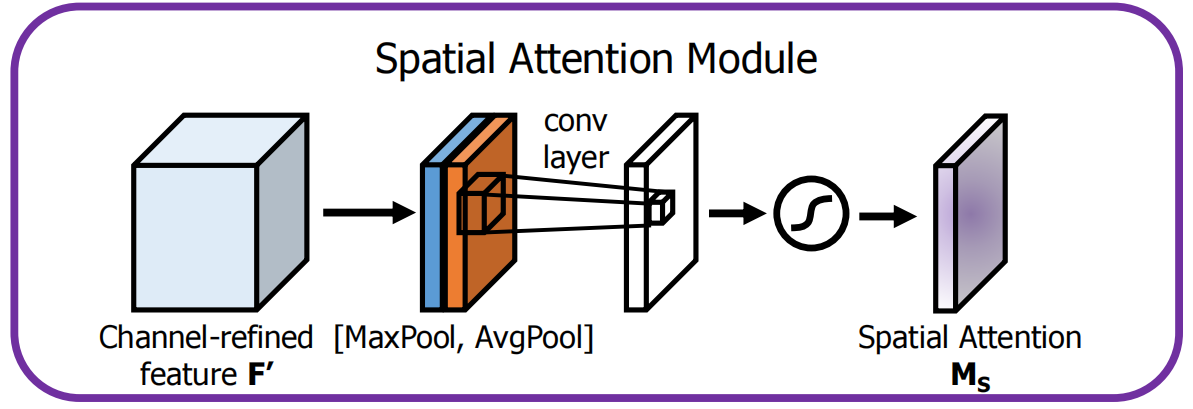
空间注意力模块首先对输入特征图沿着通道方向进行MaxPool和AvgPool操作,得到两个特征图,把两个特征图串联在一起后进行7×7卷积,得到单通道的特征图,经过softmax激活后即为空间注意力权重图,如下图所示,
写成公式,可以简单记为:
Ms(F)=σ(f7×7([AvgPool(F);MaxPool(F)]))
此种实现方式简单增强重要区域特征并抑制不相干区域特征,然而随着自注意力的爆发,空间注意力也逐渐转变为自注意力模式!
自注意力模式的空间注意力
个人认为上述的空间注意力侧重与信息的增强或抑制,起到信息过滤的作用,而自注意力则更主要的是特征提取。自注意力爆发于NLP领域,下面举一个NLP的例子,
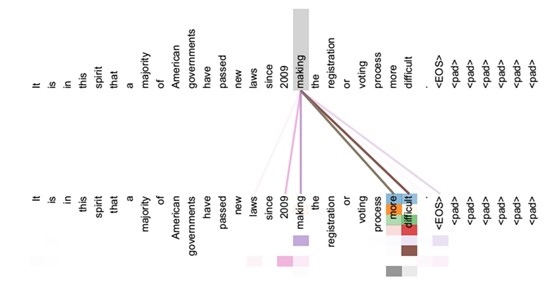
如上图所示,上层的token是下层的所有的token的加权和,不同的token对应的权重不一样,权重沿着整个序列不均匀分布,如上层making主要关注下层的making、more、difficult等。视觉任务的特征图同样可以沿着空间维度展成序列的形式,因此可以基于自注意力构建空间注意力。
自注意力最著名的计算方式是《Attention is all you need》,自注意力写成以下形式:
Attention(Q,K,V)=softmax(dkQK⊤)V
其中Q,K,V为输入X的线性映射,dk为token的维度。自注意力模式的空间注意力机制代表是 Dual Attention Network。
论文地址:Dual Attention Network for Scene Segmentation
代码地址:https://github.com/junfu1115/DANet/
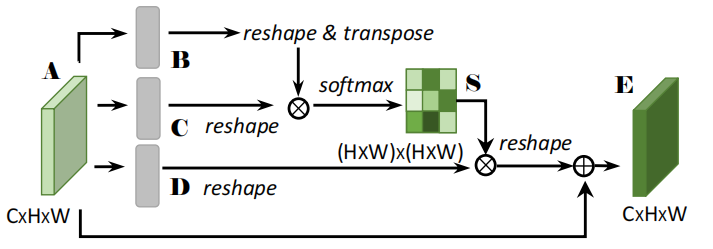
给定输入A∈RC×H×W, 首先将它输入一个卷积层生成两个新的特征图B,C∈RC×H×W,接着将B,C展开成RC×N,N=H×W, 然后计算空间注意力图 S∈N×N:
S=softmax(B⊤C)
Sji=∑i=1Nexp(Bi⋅Cj)exp(Bj⋅Cj)
与此同时A输入另外一个卷积层生成新的特征图D∈RC×H×W并reshape成 RC×N。将D与S(转置)相乘即得空间注意力的最后输出。作者还乘上一个可学习的缩放因子α并加上残差连接,即
Ej=αi=1∑N(SjiDi)+Aj
有人认为实际上起作用的是这个可学习的缩放因子α,有意思!
基于自注意力模式的空间注意力更像是一种信息聚合的过程,可视为特征提取,所以说更加强大,最新的研究基本上都是这种模式!但是,我还想研究研究用于信息过滤的空间注意力,将特征提取的任务留给主干网络,各司其职嘛!