Google Research, 2022 & Beyond: Language, Vision and Generative Models
—— Posted by Jeff Dean,谷歌2022年在AI领域的研究进展总结,窥一斑而知全豹
原博客地址:https://ai.googleblog.com/2023/01/google-research-2022-beyond-language.html
主要是看看Google在2022年做了哪些方面的研究,了解一下行业前沿!
一、语言模型
- 语言模型规模越大越牛逼!这应该是2022年体现出来的一个大趋势,而且语言模型达到一定规模之后似乎可以触发超能力,下图是Google的PaLM模型,有540B的参数,可以看到PaLM在绝大多数任务上都取得了突破。

-
语言模型还可以用来写代码,例如Google的工作:ML-Enhanced Code Completion Improves Developer Productivity。但是,引起更大轰动的是微软的Copilot,可以说相当震撼人心。
-
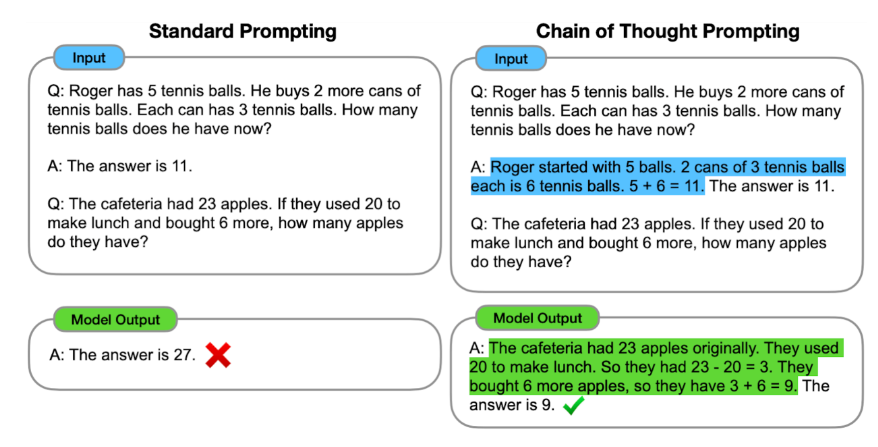
多步推理学习。人工智能的一个重要关键突破口就是要能够实现多步推理。Google的一项研究正是关注这个:Language Models Perform Reasoning via Chain of Thought,在教AI问答的时候,不是直接告诉它答案,而是告诉它结题思路,如下图所示,
二、计算机视觉
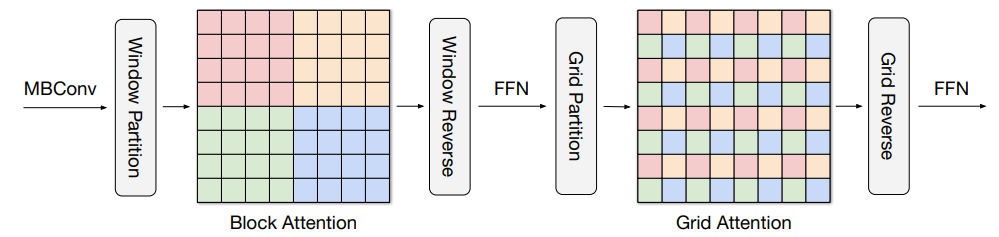
- 计算机视觉的一种重大关注点就是transformer的全面应用。计算机视觉应用transformer时需要同时关注局部和全局注意力,如:MaxViT: Multi-Axis Vision Transformer
Transformer还可用用来做目标检测,把目标检测当成翻译任务,如Pix2Seq: A Language Modeling Framework for Object Detection

- Google另外一个关注的视觉任务是如何从二维图像理解世界的三维结构,做了不少工作,如:View Synthesis with Transformers

三、多模态模型
- 继续推进Pathway,Google认定的下一代人工智能架构,统一的大模型,不仅能同时处理不同模态的数据,还可以做不同的任务,重要的是这个大模型稀疏激活,即在做特定任务时只激活相关的神经元。

多模态模型就涉及到该怎么融合数据的问题,Google的一项工作是:Multi-modal Bottleneck Transformers

多模态融合可以是图像和文字融合,如融合词嵌入做图像分类任务:Locked-image Tuning
Google设计了PaLI模型,PaLI: Scaling Language-Image Learning ,可以完成很多任务。
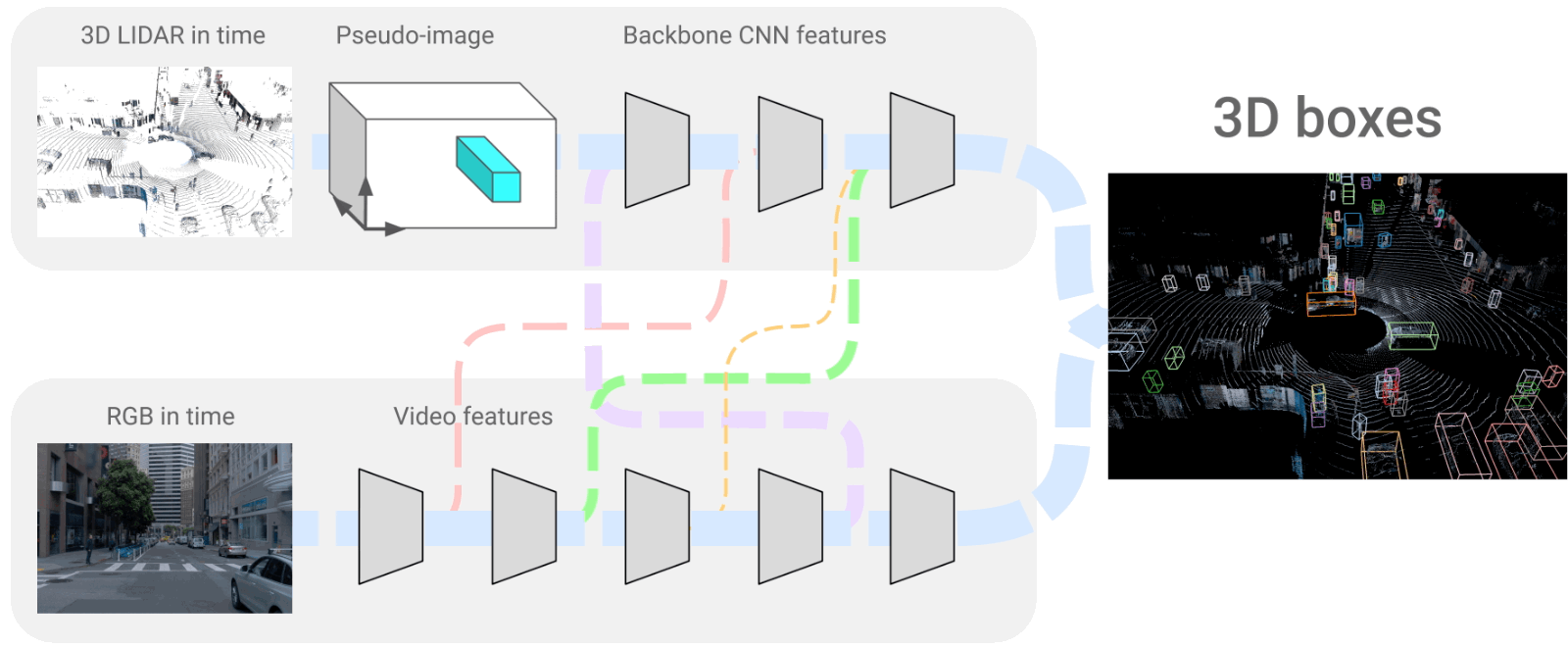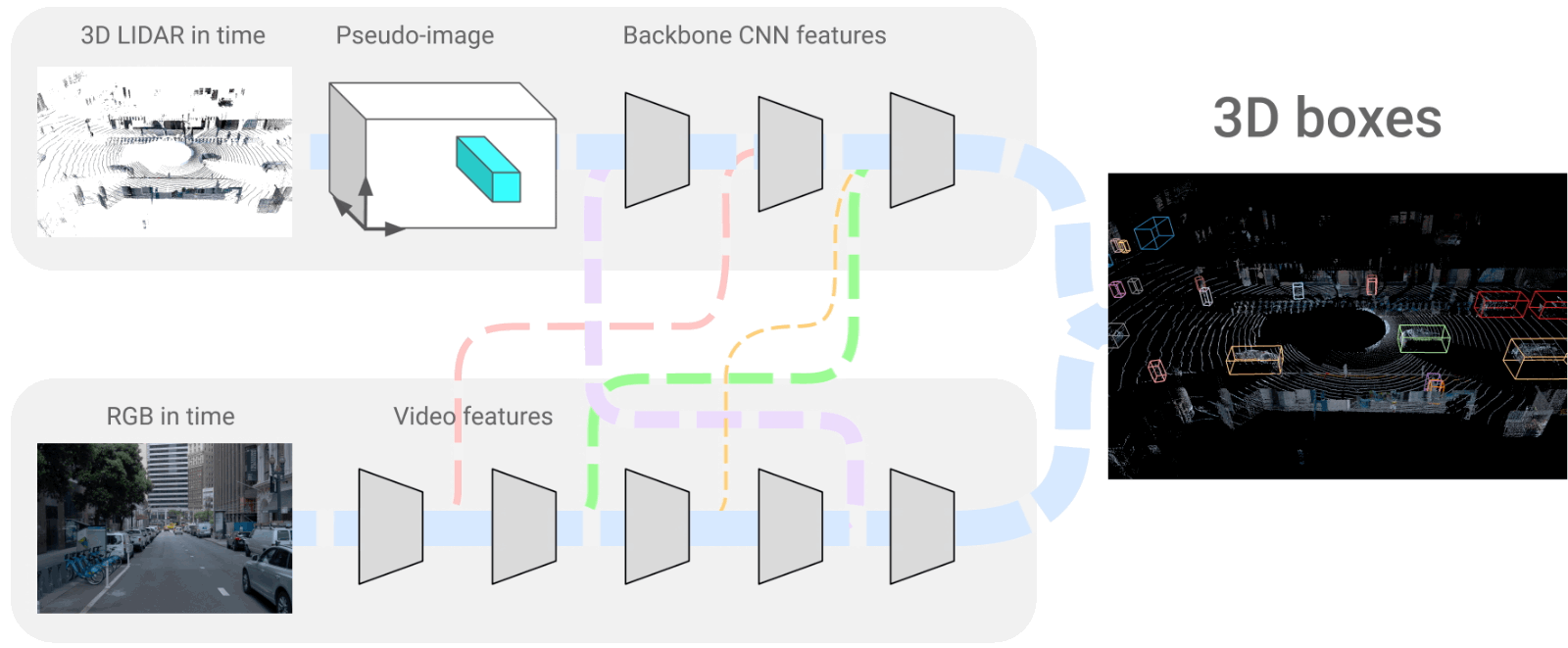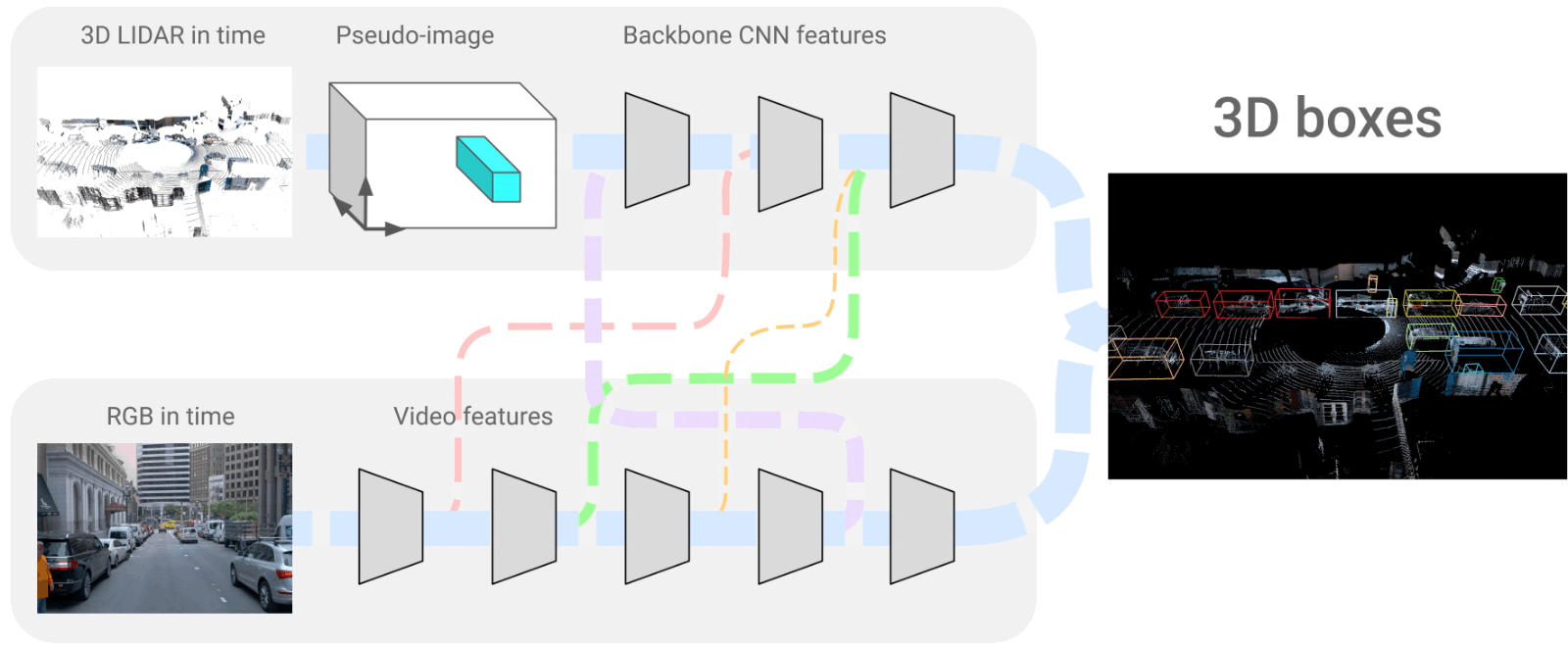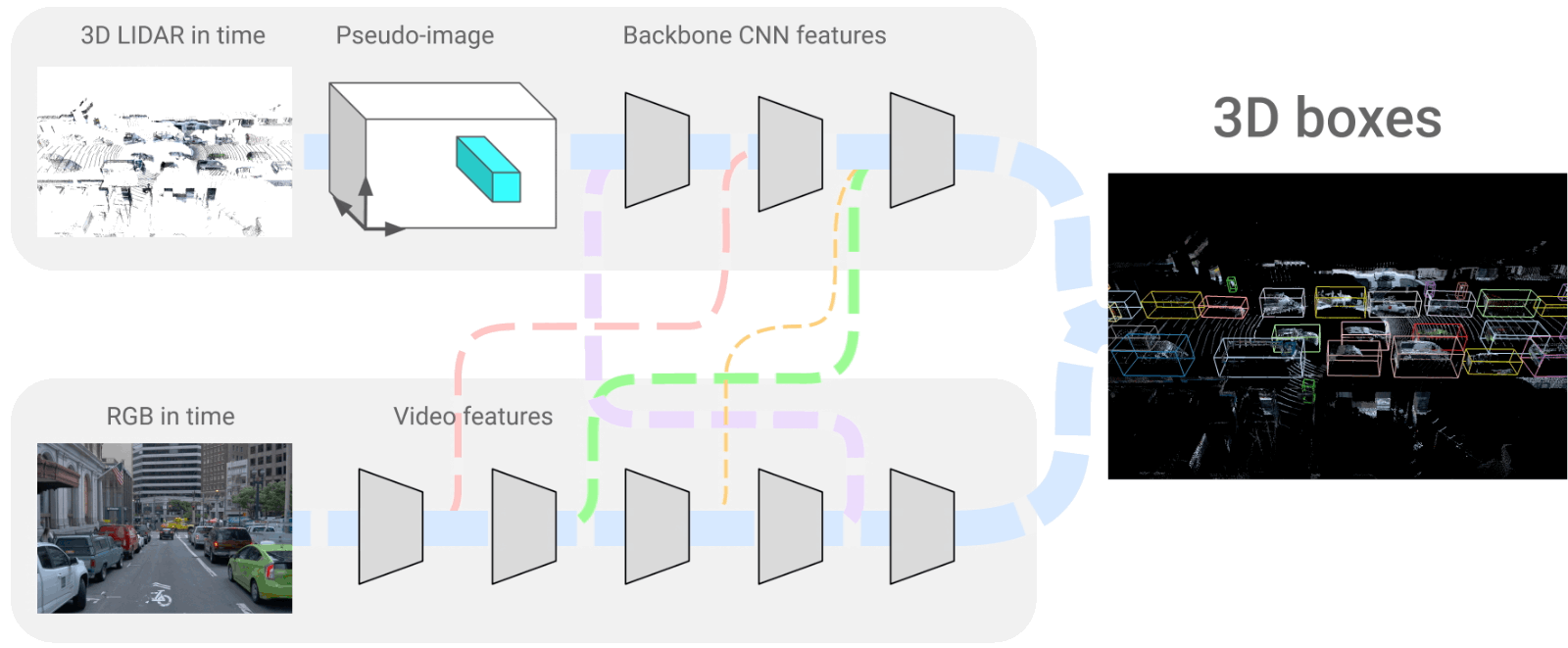
多模态数据除了可以是图像、文字、语音这些相对人类而言的多模态,还是可以是其他传感器的数据,如激光雷达等,融合激光雷达和图像做目标检测,4D-Net for Learning Multi-Modal Alignment for 3D and Image Inputs in Time
四、生成模型
- 生成模型最值得关注的就是扩散模型(Diffusion model)了。生成模型从2014年的GAN开始,到2022,算是取得了长足的进步了,生成的图像越来越好,

扩散模型就是给图像逐渐添加噪声,直到形成完全无序的噪声,这称为扩散过程;然后学习逆扩散过程,这样我们就得到了一个生成模型,能够从噪声生成图像,

扩散模型常用在Text-Image任务,根据文字生成图像,DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation

生成图像,Imagen Video: High Definition Video Generation from Diffusion Models



生成语音,AudioLM: a Language Modeling Approach to Audio Generation
https://google-research.github.io/seanet/audiolm/examples/
五、总结
最后就是对AI可靠性的关注了,特别是生成模型的发展,谁知道会不会是潘多拉的魔盒了,Google说自己特别关注AI的可靠性,制定了一些AI准则。
AI的发展确实振奋人心,NLP领域在2022年的另一个重大事件是ChatGPT 的发布,不过它是OpenAI的成果,不是Google的。