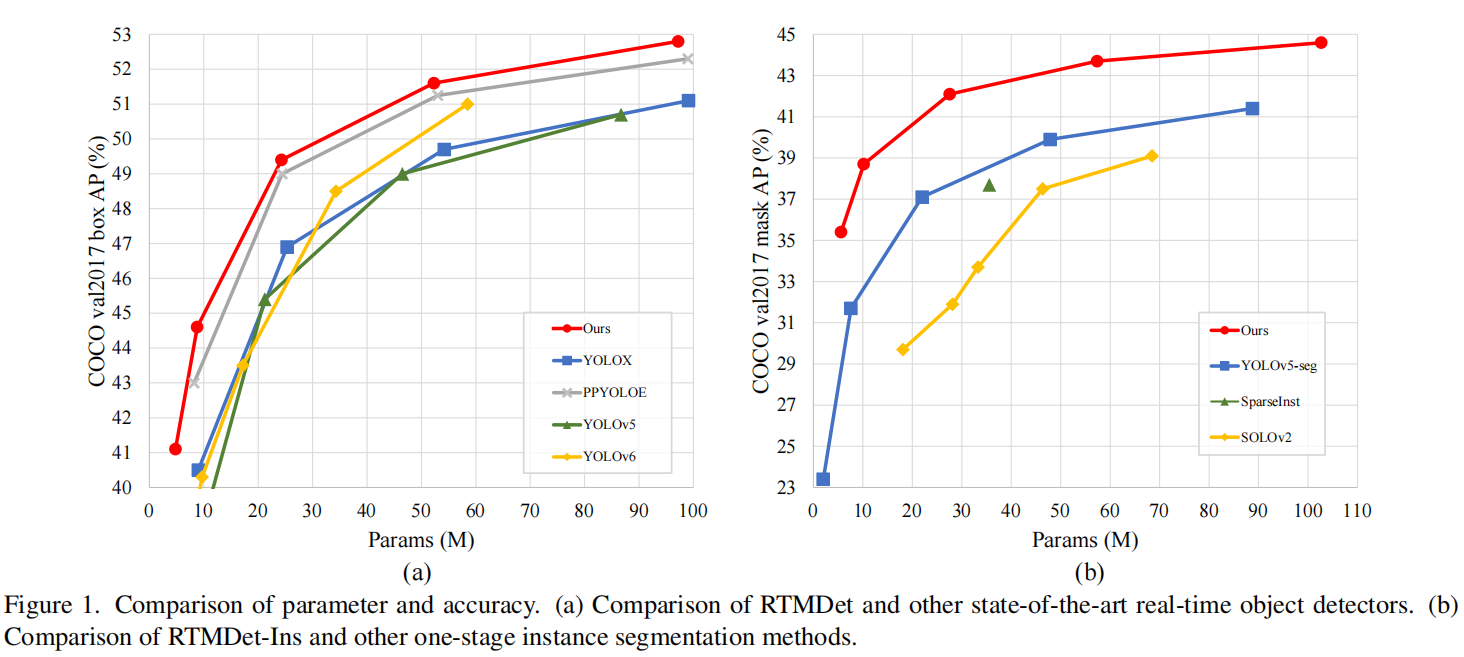
【论文阅读笔记】RTMDet: An Empirical Study of Designing Real-Time Object Detectors
论文地址:RTMDet: An Empirical Study of Designing Real-Time Object Detectors
代码地址:https://github.com/open-mmlab/mmdetection/tree/3.x/configs/rtmdet
这是一份关于如何设计实时目标检测器的实验报告,目的在于设计出超越YOLO系列的实时目标检测器,并且易于拓展到旋转目标检测和实例分割任务。
一、宏观架构
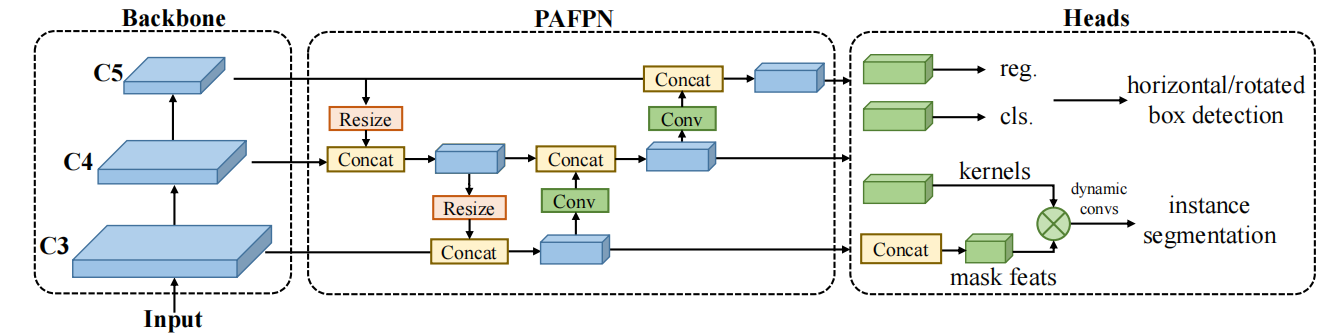
实时目标检测一直是YOLO系列等一阶段检测器的目标,所以设计团队对模型的宏观设计遵循一阶段检测器,如下图所示,主要分为backbone、neck和head。
二、模型
1、Basic building black
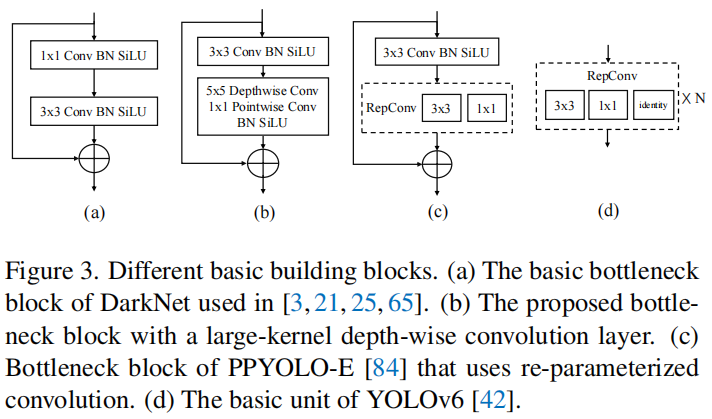
较大的有效感受野有利于像目标检测和语义分割之类的密集预测任务,因为它可以更有效地捕获和建模图像中上下文信息。然而像空洞卷积、非局部注意力这些计算复杂度较高不适合实时目标检测。最近,有研究采用更大的卷积核来增大感受野,配合深度可分离卷积,可以有效控制其计算代价。因此作者在主干网络CSPDarkNet中的基础模块中引入一个的深度可分离卷积,如下图(b)所示。
2、Balance of model width and depth
采用深度可分离卷积必须额外接一个逐点卷积层 (point-wise convolution),这样模型的深度增加,因此设计团队适当减少主干网络的每个stage的基础模块并稍微增加模型宽度。
3、Balance of backbone and neck
一个更heavier的颈部网络用于融合多尺度特征对检测不同尺度的目标十分有必要。设计团队提高颈部网络基础模块的膨胀比,以将更多参数和计算放到颈部,提高模型能力。
4、Shared detection head
不同尺度特征图共享检测头,但是得配备不同的Batch Normalization (BN)层。
5、Label assignment and losses
基于SimOTA设计动态标签分配策略,以代价函数作为分配标准,代价函数如下,
其中,和分别表示分类损失、回归损失以及区域先验损失;以及为默认参数。
在分类代价函数中,原来的SimOTA采用二进制标签计算损失,这会导致一个问题:对于某个分类分数高但边界框不正确的预测结果会得到一个较低的分类代价,反之亦然。设计团队提出计算预测结果和真实值之间的IoU作为软标签,分类代价函数如下,
回归代价函数中,原来的方法采用GIoU,这样的结果是最好的匹配和最差的匹配相差不过1,很难区分匹配质量,设计团队采用IoU的对数作为回归代价,具体如下,
原来的方法在固定中心区域内选取前个总代价最小作为真实值的正样本,在这里,设计团队加入了区域先验代价,指定了一个软中心区域,区域先验损失如下,
为默认超参数。
接下来选择个总代价最小作为正样本即可。
6、Cached Mosaic and MixUp
采用缓存技术实现Mosaic和MixUp等需要多张图片的数据增广技术,把图片放在缓存中,训练时就不需要加载多张图片就可以实现Mosaic和MixUp,极大地提高数据加载速度。
7、Two-stage training
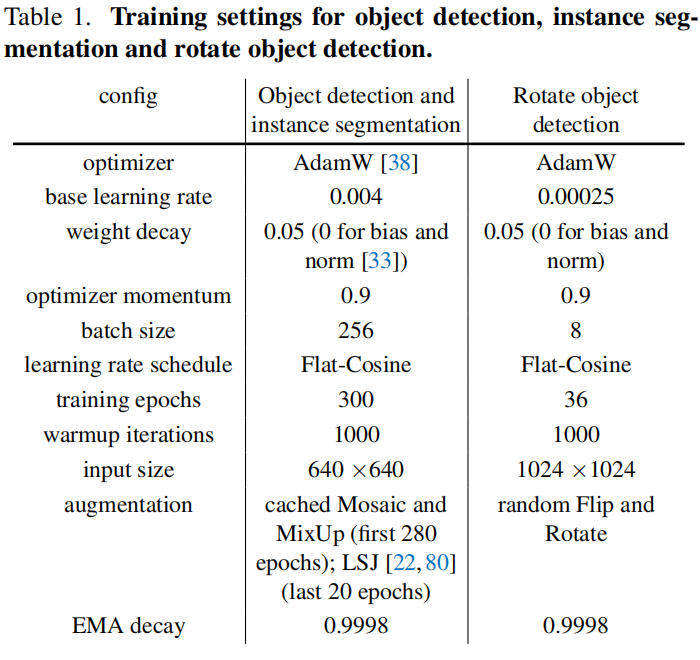
两段式训练是指将训练过程分成两个阶段,第一阶段采用强数据增广Mosaic和MixUp,第二阶段采用弱数据增广,即不用Mosaic和MixUp。YOLOX还在第二阶段引入L1损失函数来微调回归分支。在这里,设计团队不再引入L1损失函数,将第一阶段数据增广时混合图片数量提高到8,且第一阶段设置为280epochs;在最后20个epochs中采用 Large Scale Jittering (LSJ)做为数据增广。两段式训练的原因是强数据增广虽然能够提高模型的泛化性,但是会导致训练数据分布与真实分布不一致,所以需要在第二阶段使用与真实分布更接近的数据进行微调。
8、Implementation Details
9、Experimental result