【论文阅读笔记】InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
论文地址:https://arxiv.org/abs/2211.05778
代码地址:https://github.com/OpenGVLab/InternImage
一、引言
现在深度学习都去研究大模型了,不管CV还是NLP,都上大模型。这篇文章也一样,它说现在CV任务里面用的大模型都是基于transformer的,效果相当不错,可以说是横扫一切!但是,作者说卷积神经网络配合相似的算子/架构级别的精心设计,在大模型、大数据的条件下也可以做到类似、甚至更好的性能。就是说你transformer能做到的,我CNN也能做到。这篇文章充分展示了怎么去设计一个神经网络模型!值得学习~
为了设计出不弱于transformer的CNN大模型,就得先分析它们的不同之处,(1)从算子层面来看,transformer的基础模块多头注意力具有学习长距离依赖的能力以及可以进行自适应的空间信息聚合的能力(如下图(a)所示);(2)从架构层面看,transformer除了多头注意力还有其他一些先进的模块,例如Layer Normalization(LN)、Feed-forward network (FFN)、GELU等。
Transformer有优势,也有缺点,就是计算复杂度极高,为了克服这个问题,有人就对多头注意力做一些限制,使它从global attention变成local attention,这样,复杂度问题解决了,但是却牺牲了长距离依赖的学习能力(如下图(b)所示)。
为了给CNN模型引入长距离依赖的学习能力,有些工作[1-2]就采用了超级大的卷积核(比如:),但是这种超大卷积核的空间信息聚合能力不能自适应,因为卷积核的权重是固定的(如下图(c)所示)。
现有算子中恰好还有可变形卷积,它能够满足我们想要的三个性质:长距离依赖、自适应空间信息聚合以及高计算效率(如下图(d)所示)。首先,可变形卷积的采样偏移量可以灵活地从给定的数据中动态地学习适当的感受野(可以是长距离的或短距离的);其次,采样偏移量和调制标量都是针对输入数据自适应的;最后,采样常规卷积核,避免了计算复杂度爆炸,提高了计算效率。
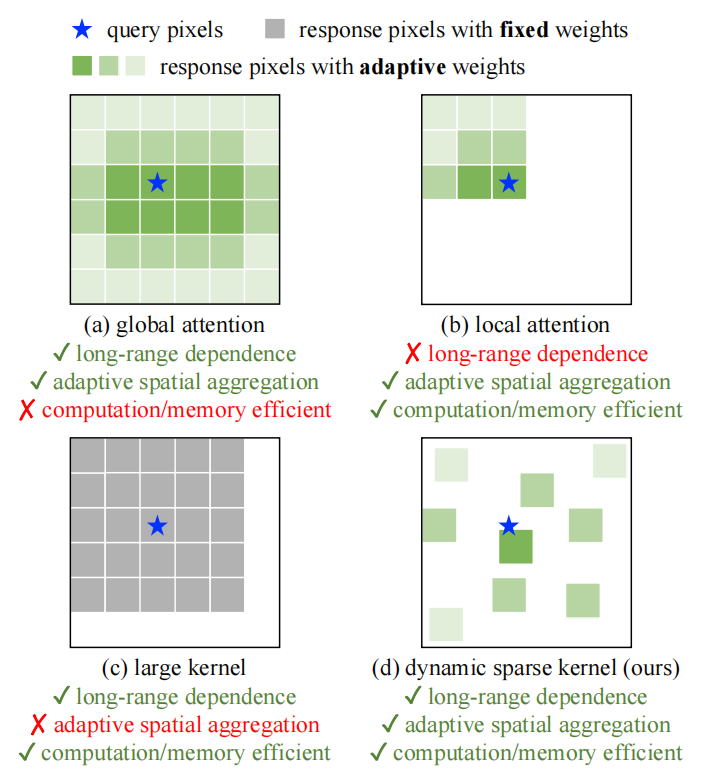
因此,本文将基于可变形卷积设计大模型。
二、InternImage模型
1、核心算子
长距离依赖。现有研究证明大的有效感受野(长距离依赖)对下游的视觉任务有用,但是常规卷积核的感受野相对很小,即便是很深的模型依然不能捕获类似于transformer的长距离依赖。
自适应空间信息聚合。与transformer根据输入动态决定权重不同,常规卷积的权重固定且具有很强的归纳偏置,比如二维局部性、近邻结构性以及平移不变性等。高归纳偏置的模型收敛更快,需要的训练数据更少,但是也限制了模型无法从大规模数据集中学习更加通用和鲁棒的表征。
(1)DCNv2回顾
同时满足上述两个性质的卷积算子的DCN。给定输入和当前像素点,DCNv2如下式所示:
其中,表示采样点的数量,如采用卷积核采样点数量则为9,遍历所有采样点。表示预定义采样网格的第个位置; 表示第个采样网格位置的偏移量,有了这个偏移量,DCN就可以灵活地学习短距离或长距离依赖。表示第个采样点的调制标量,经过函数的标准化。是第个采样点的映射权重。根据输入数据可学习的调制标量和位置偏移量 使得DCN能够进行自适应的空间信息聚合。
(2)DCVv2改造
为了适应大模型,作者对DCNv2进行改造,
1)卷积神经元(一个常规的卷积核具有9个线性映射神经元)之间共享权重。回顾一下原始的DCNv2:对于每个采样点对应的向量首先会乘上一个调制标量,然后再拿一个权重向量去乘,进行线性映射。也就是每个采样点都会对应一个不同的映射向量,这样会是得计算复杂度跟采样点数量成线性关系,作者为了提高计算效率,对每个采样点都采用同一个映射权重,即与位置无关。(其思想与深度可分离卷积类似,但并不完全一致)
2)引入多组机制。Transformer的核心算子是多头注意力,即将输入沿通道分成多个组,在每个组内分别进行运算,这样每个子空间中都可以学习不同的表征,有利于提高模型的表达能力。因此,作者引入多组机制,即分组卷积。
3)沿采样点规范化调制标量。DCNv2中每个采样点的调制标量是直接经过缩放到之间,这样调制标量的总和会在之间变化,导致训练不稳定,因此作者对所有的调制标量进行规范化,使得调制标量总和为1。
基于上述改进,作者提出了DCN v3,如下所示,
其中,表示分组数量,其他符号的意义与原来类似,表示映射权重,表示分组后每组的通道维度,表示调制标量。
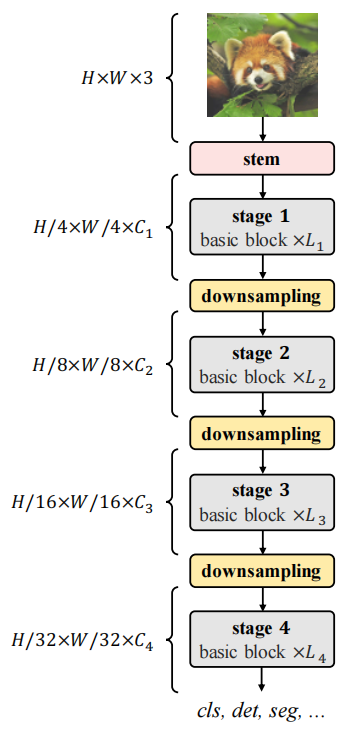
2、模型构建
(1)basic block
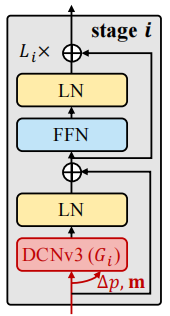
Basic block 采用transformer常用的结构设置,如下图所示,其中位置偏移量和调制标量通过一个独立卷积层(a 3×3 depth-wise convolution followed by a linear projection)来学习。
(2)Stem & downsampling layers
Stem 和 downsampling layers的设置如下,

(3)Stacking rules
Stacking rules决定了如何使用基本模块组成整体模型,首先定义几个基本符号:
: 第个stage的通道数;
: 第个stage的分组数;
: 第个stage的basic block数量;
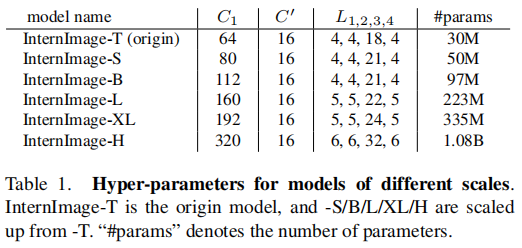
通常一个模型有4个stage,每个stage由上面3个参数决定。为降低搜索空间,作者总结前人经验,提出了4个规则:1)后3个stage的通道数由第一个通道数决定,;2)分组数由通道数决定,;3)第1、2、4stage中的basic block数量一样,即采用"AABA"的模式,;4)第3个stage的basic block数量要大于其他stage的数量,。这样,一个模型就可以由4个参数决定,分别为,然后对4个参数取不同值进行超参数搜索,最终找到基础模型的最优超参数为。
(4) Scaling rules
主要是考虑缩放模型的深度和宽度来构建大模型,记模型深度为,宽度,因子,Scaling rules为,其中,,在这里,1.99是特定于InternImage模型的,通过将模型宽度加倍并保持深度恒定来计算。
最终,各个规模的模型配置设置如下,
三、实验结果
目标检测和语义分割破纪录,COCO test-dev目标检测数据集达到65.4mAP,ADE20K语义分割数据集达到62.9 mIoU。
目标检测,用的是DINO检测器,结果如下,
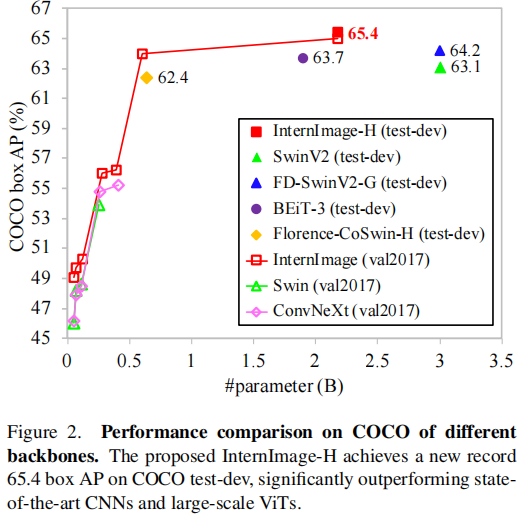
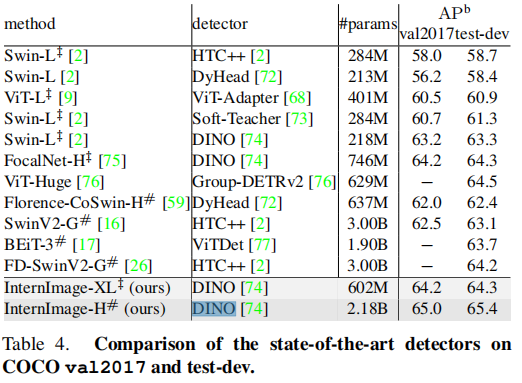
四、总结
现在transformer说要一统江湖,CNN说廉颇未老尚能再战,其实背后的思想发展脉络已经决定了未来的结局。最开始的深度神经网络是MLP,号称只要模型够大便可以拟合任意函数,只是当时算力不够,标注数据太少且质量太差,训练不出来这样的模型;因此引入归纳偏置,归纳偏置就是人类洞察的关于事物的认知,视觉任务引入高归纳偏置的CNN,语言处理引入RNN。高归纳偏置可以提高模型收敛速度和训练数据的需求。Transformer的兴起是得益于高算力和大数据,直接舍弃部分归纳偏置,直接从数据中学习更通用更鲁棒的知识。Transformer现在面临的问题是计算复杂度高,说到底还是算力不够,所以又考虑重新引入归纳偏置,比如这篇文章。现在一个很现实的考虑就是可以把这篇文章的DCNv3改造成一维卷积,这样便可以同时处理视觉任务和自然语言任务。
参考文献:
[1] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. arXiv preprint arXiv:2201.03545, 2022. 2, 3, 5, 6, 7, 8
[2] Xiaohan Ding, Xiangyu Zhang, Jungong Han, and Guiguang Ding. Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In IEEE Conf. Comput. Vis. Pattern Recog., pages 11963–11975, 2022. 2, 3, 5, 6, 7, 8