论文地址:Efficient Non-Local Contrastive Attention for Image Super-Resolution https://github.com/Zj-BinXia/ENLCA
Non-Local Contrastive Attention, 高效的非局部对比注意力 [1] !发表于AAAI 2022,属于空间注意力,用于单图像超分辨率任务。Non-Local Attention,译为非局部注意力,也就是全局注意力,通过利用自然图像中的内在特征相关性可以有效提升超分辨率的性能。但是Non-Local Attention由于自身的局限性,给图像中的噪声信息也分配了较大的权重,如下图所示,N L S A NLSA N L S A [2] 分配的注意力权重,N L S A NLSA N L S A N L S A NLSA N L S A
Non-Local Attention
Non-Local Attention 可以通过从整个图像中聚合相关特征来学习表征,一般而言,定义如下:
Y i = ∑ j = 1 N e x p ( Q i ⊤ K j ) ∑ j ^ = 1 N e x p ( Q i ⊤ K j ^ ) V j , \textbf{Y}_{i} = \sum_{j=1}^{N} \frac{exp(\textbf{Q}_{i}^{\top} \textbf{K}_{j})}{\sum_{\hat{j}=1}^{N} exp(\textbf{Q}_{i}^{\top} \textbf{K}_{\hat{j}})} \textbf{V}_{j},
Y i = j = 1 ∑ N ∑ j ^ = 1 N e x p ( Q i ⊤ K j ^ ) e x p ( Q i ⊤ K j ) V j ,
Q = θ ( X ) , K = δ ( X ) , V = φ ( X ) , \textbf{Q} = \theta (\textbf{X}), \textbf{K} = \delta (\textbf{X}), \textbf{V} = \varphi (\textbf{X}),
Q = θ ( X ) , K = δ ( X ) , V = φ ( X ) ,
实际上这就是self-attention的一般实现形式,X ∈ R c × N \textbf{X} \in \mathbb{R}^{c \times N } X ∈ R c × N N = h × w N = h \times w N = h × w θ ( . ) \theta (.) θ ( . ) δ ( . ) \delta (.) δ ( . ) φ ( . ) \varphi (.) φ ( . ) Q i , K j ∈ R c , V j ∈ R c o u t \textbf{Q}_{i}, \textbf{K}_{j} \in \mathbb{R}^{c}, \textbf{V}_{j} \in \mathbb{R}^{c_{out}} Q i , K j ∈ R c , V j ∈ R c o u t Q , K , V \textbf{Q}, \textbf{K}, \textbf{V} Q , K , V i , j i, j i , j
Non-Local Attention 第一个众所周知的缺点是其对输入尺寸二次方的复杂度,所以本文考虑的第一个点就是提升计算效率,作者考虑的是采用用核方法(Kernel Method) 去逼近Non-local Attention里面的指数函数。
Kernel Method
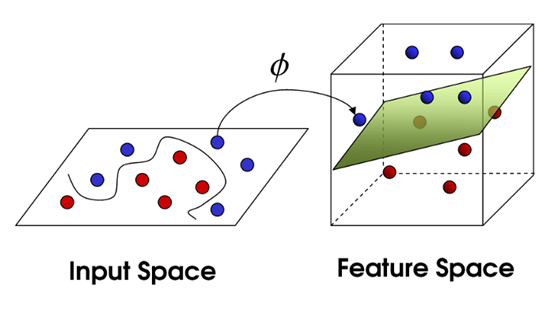
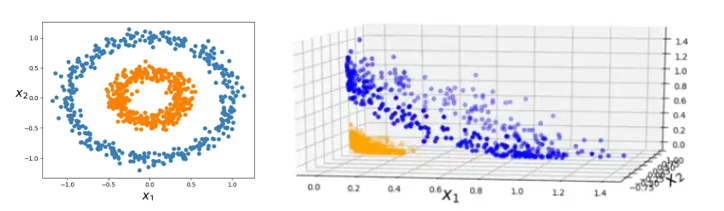
首先,机器学习分类任务中存在这么一个观察:低维空间中线性不可分的点映射到高维空间之后可能就线性可分了,所以按照这个思路,我们就应该把低维空间的点映射到高维空间再进行分类,因为在高维空间中是线性可分的。
对于线性模型f ( x ) = w ⊤ x f(\textbf{x})=\textbf{w}^{\top}\textbf{x} f ( x ) = w ⊤ x w ∗ = ∑ i = i N α i x i \textbf{w}^{*}=\sum^{N}_{i=i} \alpha _{i} \textbf{x}_{i} w ∗ = ∑ i = i N α i x i
f ∗ ( x ) = ∑ i = 1 N α i x i ⊤ x f^{*}(\textbf{x})=\sum_{i=1}^{N} \alpha _{i} \textbf{x}_{i}^{\top} \textbf{x}
f ∗ ( x ) = i = 1 ∑ N α i x i ⊤ x
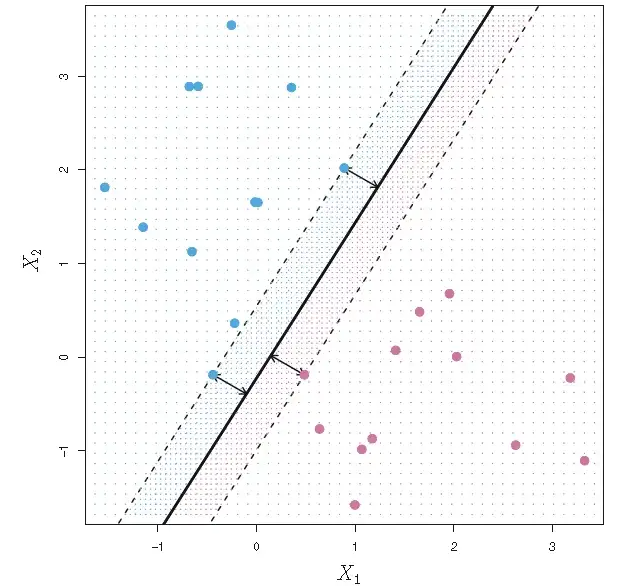
其实,对核方法理解的难点就在于这里:为什么线性模型的最优解是所有数据样本的线性组合?如果要严格去理论证明这件事可能需要用到表示定理(representer theorem)或者拉格朗日乘子法等知识,这些我已经忘得差不多了,以后再补补吧!在这里,我们举例子简单理解一下,例如在二维空间中,如下图所示有正负两类样本,其中分类边界就是中间的那条线,在线的这边属于一类,另一边属于另一类。显然,这条线是可以有所有数据样本线性组合得到的,分类的关键是怎么对这些数据样本进行线性组合,当然也不是所有的数据样本都对这条分类边界有用。在这里我们不讨论这些,只需要理解分类边界可以由所有数据样本线性组合得到 ,这样我们就将求权重w ∗ w^{*} w ∗ α \alpha α
但是,对于开头提到的低维空间中线性不可分的情况,我们就需要将其映射到高维空间中,即引入映射 ϕ : X → H \phi : \mathcal{X} \to \mathcal{H} ϕ : X → H H \mathcal{H} H F \mathcal{F} F
f ∗ ( x ) = ∑ i = 1 N α i ϕ ( x i ) ⊤ ϕ ( x ) f^{*}(\textbf{x})=\sum_{i=1}^{N} \alpha _{i} \phi(\textbf{x}_{i})^{\top} \phi(\textbf{x})
f ∗ ( x ) = i = 1 ∑ N α i ϕ ( x i ) ⊤ ϕ ( x )
但是,特征变换映射ϕ ( x ) \phi(\textbf{x}) ϕ ( x ) ϕ ( x i ) ⊤ ϕ ( x ) \phi(\textbf{x}_{i})^{\top} \phi(\textbf{x}) ϕ ( x i ) ⊤ ϕ ( x ) ϕ ( x ) ⊤ ϕ ( x ′ ) \phi(\textbf{x})^{\top} \phi(\textbf{x}^{'}) ϕ ( x ) ⊤ ϕ ( x ′ )
我们先来看一个简单的例子:
还是一个二维映射到三维的例子,我们假设映射函数为:
ϕ ( x ) = ϕ ( ( x 1 x 2 ) ) = ( x 1 2 2 x 1 x 2 x 2 2 ) \phi(\textbf{x})=\phi(\begin{pmatrix}x_{1}\\x_{2}\end{pmatrix}) = \begin{pmatrix}x_{1}^{2}\\\sqrt{2} x_{1} x_{2} \\ x_{2}^{2}\end{pmatrix}
ϕ ( x ) = ϕ ( ( x 1 x 2 ) ) = ⎝ ⎛ x 1 2 2 x 1 x 2 x 2 2 ⎠ ⎞
那么,假如我们现在要求向量a , b \textbf{a},\textbf{b} a , b
ϕ ( a ) ⊤ ⋅ ϕ ( b ) = ( a 1 2 2 a 1 a 2 a 2 2 ) ⋅ ( b 1 2 2 b 1 b 2 b 2 2 ) = a 1 2 b 1 2 + 2 a 1 b 1 a 2 b 2 + a 2 2 b 2 2 = ( a 1 b 1 + a 2 b 2 ) 2 = ( ( a 1 a 2 ) ⊤ ⋅ ( b 1 b 2 ) ) 2 = ( a ⊤ ⋅ b ) 2 \phi(\textbf{a})^{\top} \cdot \phi(\textbf{b}) = \begin{pmatrix}a_{1}^{2}\\\sqrt{2} a_{1} a_{2} \\ a_{2}^{2}\end{pmatrix} \cdot \begin{pmatrix}b_{1}^{2}\\\sqrt{2} b_{1} b_{2} \\ b_{2}^{2}\end{pmatrix}=a_{1}^{2}b_{1}^{2}+2a_{1}b_{1}a_{2}b_{2}+a_{2}^{2}b_{2}^{2} \\ =(a_{1}b_{1}+a_{2}b_{2})^{2} = (\begin{pmatrix}a_{1}\\a_{2}\end{pmatrix}^{\top} \cdot \begin{pmatrix}b_{1}\\b_{2}\end{pmatrix})^{2}=(\textbf{a}^{\top} \cdot \textbf{b})^{2}
ϕ ( a ) ⊤ ⋅ ϕ ( b ) = ⎝ ⎛ a 1 2 2 a 1 a 2 a 2 2 ⎠ ⎞ ⋅ ⎝ ⎛ b 1 2 2 b 1 b 2 b 2 2 ⎠ ⎞ = a 1 2 b 1 2 + 2 a 1 b 1 a 2 b 2 + a 2 2 b 2 2 = ( a 1 b 1 + a 2 b 2 ) 2 = ( ( a 1 a 2 ) ⊤ ⋅ ( b 1 b 2 ) ) 2 = ( a ⊤ ⋅ b ) 2
也就是说两个向量映射到三维空间后的内积实际上等于其在二维空间中的内积的平方,我们把k ( a , b ) = ϕ ( a ) ⊤ ⋅ ϕ ( b ) k(\textbf{a},\textbf{b})=\phi(\textbf{a})^{\top} \cdot \phi(\textbf{b}) k ( a , b ) = ϕ ( a ) ⊤ ⋅ ϕ ( b ) ( a ⊤ ⋅ b ) 2 (\textbf{a}^{\top} \cdot \textbf{b})^{2} ( a ⊤ ⋅ b ) 2
核函数定义: 设X \mathcal{X} X R n 的 子 集 或 离 散 集 合 \mathbf{R}^{n}的子集或离散集合 R n 的 子 集 或 离 散 集 合 H \mathcal{H} H X \mathcal{X} X H \mathcal{H} H
ϕ : X → H \phi : \mathcal{X} \to \mathcal{H}
ϕ : X → H
使得对所有x , z ∈ X \textbf{x},\textbf{z} \in \mathcal{X} x , z ∈ X k ( x , z ) k(\textbf{x},\textbf{z}) k ( x , z )
k ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) k(\textbf{x},\textbf{z}) = \phi(\textbf{x}) \cdot \phi(\textbf{z})
k ( x , z ) = ϕ ( x ) ⋅ ϕ ( z )
则称k ( x , z ) k(\textbf{x},\textbf{z}) k ( x , z ) ϕ ( x ) \phi(\textbf{x}) ϕ ( x ) ϕ ( x ) ⋅ ϕ ( z ) \phi(\textbf{x}) \cdot \phi(\textbf{z}) ϕ ( x ) ⋅ ϕ ( z ) ϕ ( x ) \phi(\textbf{x}) ϕ ( x ) ϕ ( z ) \phi(\textbf{z}) ϕ ( z )
最后一个问题:核函数怎么来的呢?随便写的吗?有人说核函数的确定并不困难,满足Mercer定理的函数都可以作为核函数,但是我不会。我只知道一些常用的核函数。
常见核函数如下:
(1)线性核函数:
k ( x , z ) = x ⊤ z k(\textbf{x},\textbf{z})=\textbf{x}^{\top}\textbf{z}
k ( x , z ) = x ⊤ z
(2)多项式核函数:
k ( x , z ) = ( ζ + γ x ⊤ z ) q , ζ ≥ 0 , γ > 0 k(\textbf{x},\textbf{z})=(\zeta + \gamma \textbf{x}^{\top}\textbf{z})^{q}, \zeta \ge 0, \gamma >0
k ( x , z ) = ( ζ + γ x ⊤ z ) q , ζ ≥ 0 , γ > 0
(3)高斯核函数
k ( x , z ) = e x p ( − γ ∣ ∣ x − z ∣ ∣ 2 ) k(\textbf{x},\textbf{z})= exp(-\gamma||\textbf{x}-\textbf{z}||^{2})
k ( x , z ) = e x p ( − γ ∣ ∣ x − z ∣ ∣ 2 )
(4)拉普拉斯核函数
k ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ σ ) k(\textbf{x},\textbf{z})= exp(-\frac{||\textbf{x}-\textbf{z}||}{\sigma})
k ( x , z ) = e x p ( − σ ∣ ∣ x − z ∣ ∣ )
(5)……
对于一个核函数,总能找到一个对应的映射ϕ ( ⋅ ) \phi(\cdot) ϕ ( ⋅ )
核方法是一种手段,一种trick,所以也叫kernel trick。Kernel trick 适合用于解决此类需要将低维输入空间映射到高维特征空间且目标函数包含映射后高维特征向量内积的问题,kernel trick可以直接用核函数直接替代内积,甚至不用知道映射函数ϕ ( x ) \phi(\textbf{x}) ϕ ( x )
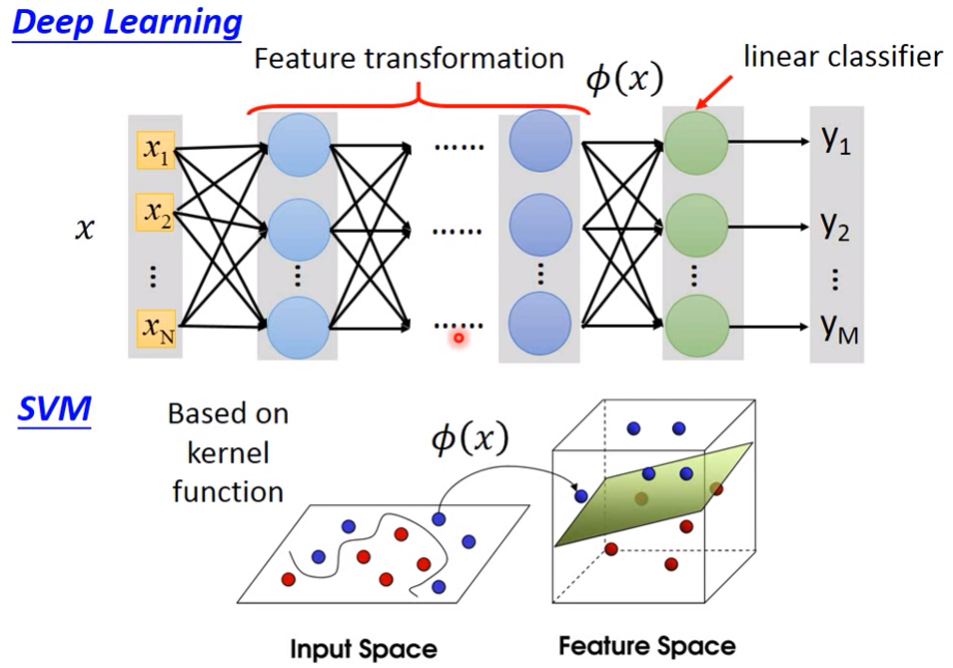
Kernel trick可以说是经典机器学习方法中一种非常漂亮的理论了,这里只能给出一个粗浅的理解,深入理解请参考网上的教程 [3] 。用到kernel trick的比较经典的机器学习方法就是SVM了,详情请参考大佬的文章[4] 。最后提一句深度学习与kernel-based方法的区别,如下图所示,深度学习实际上真的就是把低维空间的点映射到高维空间再进行分类,在Efficient Non-Local Contrastive Attention这篇文章中作者也是这样用的。
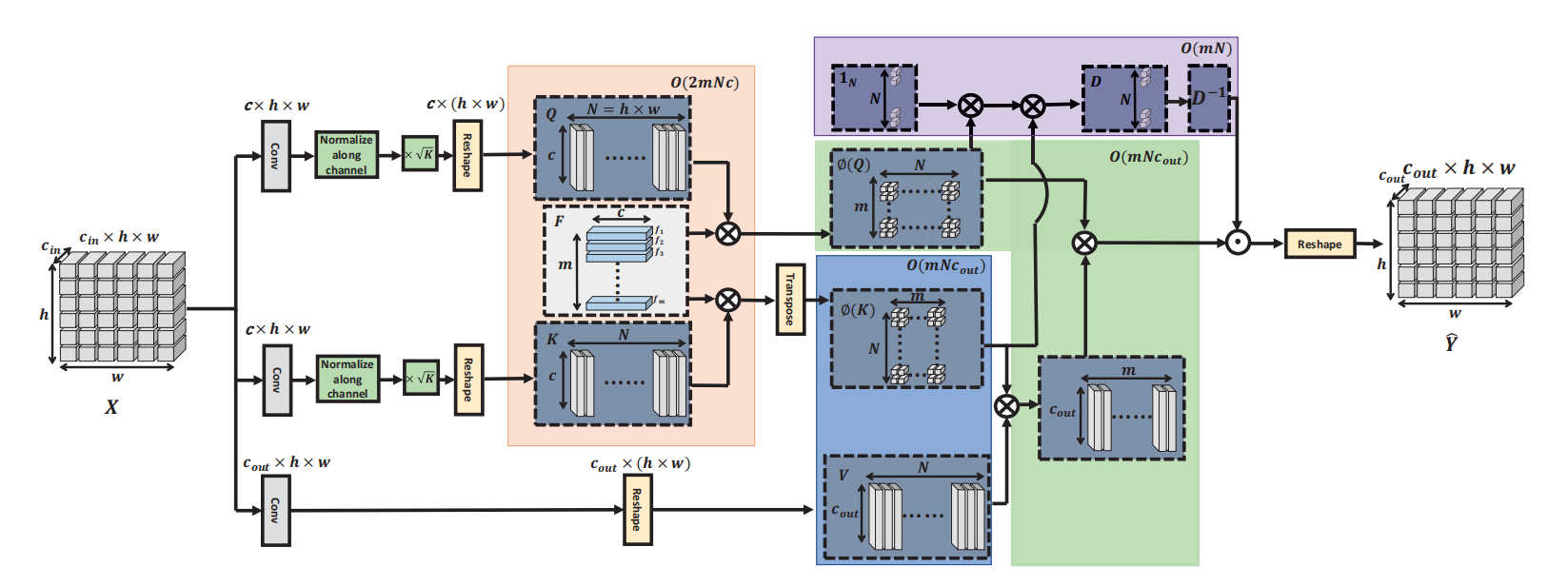
Efficient Non-Local Attention
Efficient Non-local Attention的架构如上图所示,为了给相干的特征更大的权重,忽略不相干特征,作者给输入的Q \textbf{Q} Q K \textbf{K} K k k k k k k 0.1 0.1 0 . 1 0.9 0.9 0 . 9 0.6 : 5.4 0.6 : 5.4 0 . 6 : 5 . 4 Q \textbf{Q} Q K \textbf{K} K k \sqrt{k} k
Q = k θ ( X ) ∣ ∣ θ ( X ) ∣ ∣ , K = k δ ( X ) ∣ ∣ θ ( X ) ∣ ∣ , V = φ ( X ) , \textbf{Q} = \sqrt{k} \frac{\theta (\textbf{X})}{||\theta (\textbf{X})||}, \textbf{K} = \sqrt{k} \frac{\delta (\textbf{X})}{||\theta (\textbf{X})||}, \textbf{V} = \varphi(\textbf{X}),
Q = k ∣ ∣ θ ( X ) ∣ ∣ θ ( X ) , K = k ∣ ∣ θ ( X ) ∣ ∣ δ ( X ) , V = φ ( X ) ,
作者考虑用核方法(Kernel Method) 去逼近Non-local Attention里面的指数函数。那么设核函数为:
K ( Q i , K j ) = e x p ( Q i ⊤ K j ) = e x p ( ( ∣ ∣ Q i + K j ∣ ∣ 2 − ∣ Q i ∣ ∣ 2 − ∣ ∣ K j ∣ ∣ 2 ) / 2 ) = e x p ( − ( ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) / 2 ) e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) \begin{aligned}
&\ K(\textbf{Q}_{i}, \textbf{K}_{j}) = exp(\textbf{Q}_{i}^{\top} \textbf{K}_{j}) \\
&=exp((||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} - |\textbf{Q}_{i}||^{2} - ||\textbf{K}_{j}||^{2}) / 2) \\
&=exp(- (||\textbf{Q}_{i}||^{2}+||\textbf{K}_{j}||^{2}) / 2) exp(||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} / 2) \\
\end{aligned} K ( Q i , K j ) = e x p ( Q i ⊤ K j ) = e x p ( ( ∣ ∣ Q i + K j ∣ ∣ 2 − ∣ Q i ∣ ∣ 2 − ∣ ∣ K j ∣ ∣ 2 ) / 2 ) = e x p ( − ( ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) / 2 ) e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 )
定义高斯随机样本为f ∈ R c \textbf{f} \in \mathbb{R}^{c} f ∈ R c f ∼ N ( 0 c , I c ) \textbf{f} \sim \mathcal{N}(\textbf{0}_{c},\textbf{I}_{c}) f ∼ N ( 0 c , I c ) Q i , K j ∈ R c \textbf{Q}_{i},\textbf{K}_{j} \in \mathcal{R}^{c} Q i , K j ∈ R c
( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f − ( Q i + K j ) ∣ ∣ 2 / 2 ) d f = 1 (2\pi)^{-c/2} \int exp(-||\textbf{f}-(\textbf{Q}_{i}+\textbf{K}_{j})||^{2} /2)d\textbf{f}=1
( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f − ( Q i + K j ) ∣ ∣ 2 / 2 ) d f = 1
(这个公式我没看懂!),根据该公式,核函数中的e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) exp(||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} / 2) e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 )
e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) = ( 2 π ) − c / 2 e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) ⋅ ∫ e x p ( − ∣ ∣ f − ( Q i + K j ) ∣ ∣ 2 / 2 ) d f = ( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f ∣ ∣ 2 / 2 + f ⊤ ( Q i + K j ) − ∣ ∣ Q i + K j ∣ ∣ 2 / 2 + ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) d f = ( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f ∣ ∣ 2 / 2 + f ⊤ ( Q i + K j ) ) d f = ( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f ∣ ∣ 2 / 2 ) ⋅ e x p ( f ⊤ ( Q i + K j ) ) d f = E f ∼ N ( 0 c , I c ) [ e x p ( f ⊤ ( Q i + K j ) ) ] \begin{aligned}
&exp(||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} / 2) = (2\pi)^{-c/2} exp(||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} / 2) \cdot \int exp(-||\textbf{f}-(\textbf{Q}_{i}+\textbf{K}_{j})||^{2} /2)d\textbf{f} \\
&=(2\pi)^{-c/2} \int exp(-||\textbf{f}||^{2}/2+\textbf{f}^{\top}(\textbf{Q}_{i}+\textbf{K}_{j})-||\textbf{Q}_{i}+\textbf{K}_{j}||^{2}/2+||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} / 2) d \textbf{f}\\
&=(2\pi)^{-c/2} \int exp(-||\textbf{f}||^{2}/2+\textbf{f}^{\top}(\textbf{Q}_{i}+\textbf{K}_{j}))d \textbf{f}\\
&=(2\pi)^{-c/2} \int exp(-||\textbf{f}||^{2}/2) \cdot exp(\textbf{f}^{\top}(\textbf{Q}_{i}+\textbf{K}_{j})) d \textbf{f} \\
&= \mathbb{E}_{f \sim \mathcal{N}(\textbf{0}_{c},\textbf{I}_{c})} [exp(\textbf{f}^{\top}(\textbf{Q}_{i}+\textbf{K}_{j}))]
\end{aligned} e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) = ( 2 π ) − c / 2 e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) ⋅ ∫ e x p ( − ∣ ∣ f − ( Q i + K j ) ∣ ∣ 2 / 2 ) d f = ( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f ∣ ∣ 2 / 2 + f ⊤ ( Q i + K j ) − ∣ ∣ Q i + K j ∣ ∣ 2 / 2 + ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) d f = ( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f ∣ ∣ 2 / 2 + f ⊤ ( Q i + K j ) ) d f = ( 2 π ) − c / 2 ∫ e x p ( − ∣ ∣ f ∣ ∣ 2 / 2 ) ⋅ e x p ( f ⊤ ( Q i + K j ) ) d f = E f ∼ N ( 0 c , I c ) [ e x p ( f ⊤ ( Q i + K j ) ) ]
那么,核函数最终为:
K ( Q i , K j ) = e x p ( Q i ⊤ K j ) = e x p ( − ( ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) / 2 ) e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) = E f ∼ N ( 0 c , I c ) e x p ( f ⊤ ( Q i + K j ) − ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 2 ) = ϕ ( Q i ) ⊤ ϕ ( K j ) \begin{aligned}
&\ K(\textbf{Q}_{i}, \textbf{K}_{j}) = exp(\textbf{Q}_{i}^{\top} \textbf{K}_{j})\\
&=exp(- (||\textbf{Q}_{i}||^{2}+||\textbf{K}_{j}||^{2}) / 2) exp(||\textbf{Q}_{i}+\textbf{K}_{j}||^{2} / 2) \\
&= \mathbb{E}_{f \sim \mathcal{N}(\textbf{0}_{c},\textbf{I}_{c})} exp(\textbf{f}^{\top}(\textbf{Q}_{i}+\textbf{K}_{j}) - \frac{||\textbf{Q}_{i}||^{2}+||\textbf{K}_{j}||^{2}}{2}) \\
&=\phi(\textbf{Q}_{i})^{\top} \phi(\textbf{K}_{j})
\end{aligned} K ( Q i , K j ) = e x p ( Q i ⊤ K j ) = e x p ( − ( ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) / 2 ) e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 / 2 ) = E f ∼ N ( 0 c , I c ) e x p ( f ⊤ ( Q i + K j ) − 2 ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) = ϕ ( Q i ) ⊤ ϕ ( K j )
在实作上,作者用了m m m f 1 , ⋯ , f m ∼ i . i . d N ( 0 c , I c ) \textbf{f}_{1}, \cdots, \textbf{f}_{m} \overset{i.i.d}{\sim} \mathcal{N}(\textbf{0}_{c},\textbf{I}_{c}) f 1 , ⋯ , f m ∼ i . i . d N ( 0 c , I c ) F ∈ R m × c \textbf{F} \in \mathbb{R}^{m\times c} F ∈ R m × c e x p ( Q i ⊤ K j ) exp(\textbf{Q}_{i}^{\top} \textbf{K}_{j}) e x p ( Q i ⊤ K j ) ϕ ( Q i ⊤ ) ϕ ( K j ) \phi(\textbf{Q}_{i}^{\top})\phi(\textbf{K}_{j}) ϕ ( Q i ⊤ ) ϕ ( K j )
ϕ ( u ) = 1 m e x p ( − ∣ ∣ u ∣ ∣ 2 / 2 ) e x p ( Fu ) \phi(\textbf{u}) = \frac{1}{\sqrt{m}} exp(-||\textbf{u}||^{2}/2) exp(\textbf{F} \textbf{u})
ϕ ( u ) = m 1 e x p ( − ∣ ∣ u ∣ ∣ 2 / 2 ) e x p ( F u )
基于上述分解和矩阵结合律,Efficient Non-Local Attention可以表示为:
Y ^ = D − 1 ( ϕ ( Q ) ⊤ ( ϕ ( K ) V ⊤ ) ) , D = d i a g [ ϕ ( Q ) ⊤ ( ϕ ( K ) 1 N ) ] \hat{\textbf{Y}} = \textbf{D}^{-1}(\phi(\textbf{Q})^{\top}(\phi(\textbf{K})\textbf{V}^{\top})), \\
\textbf{D} = diag [\phi(\textbf{Q})^{\top}(\phi(\textbf{K})\textbf{1}_{N})] Y ^ = D − 1 ( ϕ ( Q ) ⊤ ( ϕ ( K ) V ⊤ ) ) , D = d i a g [ ϕ ( Q ) ⊤ ( ϕ ( K ) 1 N ) ]
整个Efficient Non-Local Attention模块的实现师姐可以参考上图。经过上述改造,整个模块的复杂度为O ( 2 m N c + 2 m N c o u t + m N ) \mathcal{O}(2mNc+2mNc_{out}+mN) O ( 2 m N c + 2 m N c o u t + m N )
Efficient Non-Local Attention还存在一个问题,即随着核函数K ( Q i , K j ) K(\textbf{Q}_{i}, \textbf{K}_{j}) K ( Q i , K j ) ϕ ( Q i ) ⊤ ϕ ( K j ) \phi(\textbf{Q}_{i})^{\top} \phi(\textbf{K}_{j}) ϕ ( Q i ) ⊤ ϕ ( K j )
V a r ( ϕ ( Q i ) ⊤ ϕ ( K j ) ) = 1 m e x p ( − ( ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) ) V a r ( e x p ( f ⊤ ( Q i + K j ) ) ) = 1 m K 2 ( Q i , K j ∣ ) ( e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 ) − 1 ) \begin{aligned}
Var(\phi(\textbf{Q}_{i})^{\top} \phi(\textbf{K}_{j})) &= \frac{1}{m} exp(-(||\textbf{Q}_{i}||^{2} + ||\textbf{K}_{j}||^{2})) Var(exp(\textbf{f}^{\top}(\textbf{Q}_{i}+\textbf{K}_{j}))) \\
&=\frac{1}{m} K^{2}(\textbf{Q}_{i}, \textbf{K}_{j}|)(exp(||\textbf{Q}_{i}+\textbf{K}_{j}||^{2})-1)
\end{aligned} V a r ( ϕ ( Q i ) ⊤ ϕ ( K j ) ) = m 1 e x p ( − ( ∣ ∣ Q i ∣ ∣ 2 + ∣ ∣ K j ∣ ∣ 2 ) ) V a r ( e x p ( f ⊤ ( Q i + K j ) ) ) = m 1 K 2 ( Q i , K j ∣ ) ( e x p ( ∣ ∣ Q i + K j ∣ ∣ 2 ) − 1 )
所以放大因子k k k
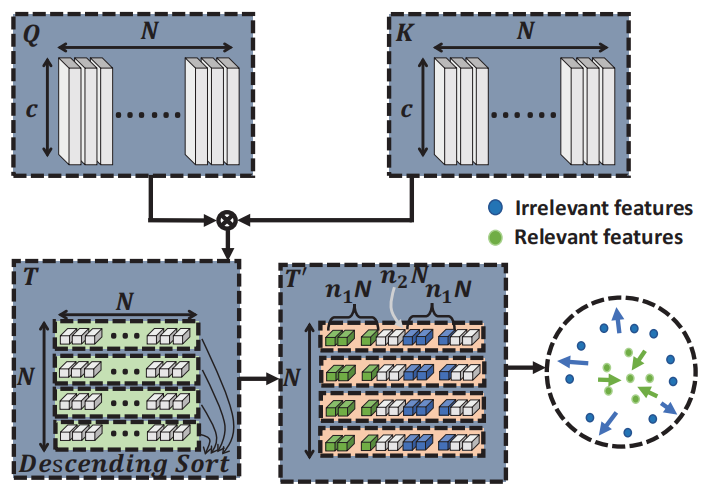
Contrastive Learning for Sparse Aggragation
整个对比学习方案如下图所示:
对于Query矩阵Q Q Q K K K
T i , j = k Q i ⊤ ∣ ∣ Q i ∣ ∣ K j ∣ ∣ K j ∣ ∣ , k > 1 , T i , j ∈ T , \textbf{T}_{i,j} = k \frac{ \textbf{Q}_{i}^{\top}}{ || \textbf{Q}_{i} || } \frac{\textbf{K}_{j}}{||\textbf{K}_{j}||}, k > 1, \textbf{T}_{i,j} \in \textbf{T},
T i , j = k ∣ ∣ Q i ∣ ∣ Q i ⊤ ∣ ∣ K j ∣ ∣ K j , k > 1 , T i , j ∈ T ,
然后对相似度向量T i \textbf{T}_{i} T i
T i ′ = s o r t ( T i , D e s c e n d i n g ) , T i ′ ∈ T ′ , T i ∈ T \textbf{T}_{i}^{'} = sort(\textbf{T}_{i}, Descending), \textbf{T}_{i}^{'} \in \textbf{T}^{'}, \textbf{T}_{i} \in \textbf{T}
T i ′ = s o r t ( T i , D e s c e n d i n g ) , T i ′ ∈ T ′ , T i ∈ T
最后,设计对比学习的损失函数L c l \mathcal{L}_{cl} L c l
L c l = 1 N ∑ i = 1 N − l o g ∑ j = 1 n 1 N e x p ( T i , j ′ ) / n 1 N ∑ n 2 N ( n 1 + n 2 ) N e x p ( T i , j ′ ) / n 1 N + b , \mathcal{L}_{cl} = \frac{1}{N} \sum_{i=1}^{N} - log \frac{\sum_{j=1}^{n_{1}N}exp(\textbf{T}_{i,j}^{'})/n_{1}N}{\sum_{n_{2}N}^{(n_{1}+n_{2})N}exp(\textbf{T}_{i,j}^{'})/n_{1}N} + b,
L c l = N 1 i = 1 ∑ N − l o g ∑ n 2 N ( n 1 + n 2 ) N e x p ( T i , j ′ ) / n 1 N ∑ j = 1 n 1 N e x p ( T i , j ′ ) / n 1 N + b ,
n 1 n_{1} n 1 n 2 n_{2} n 2
实验结果
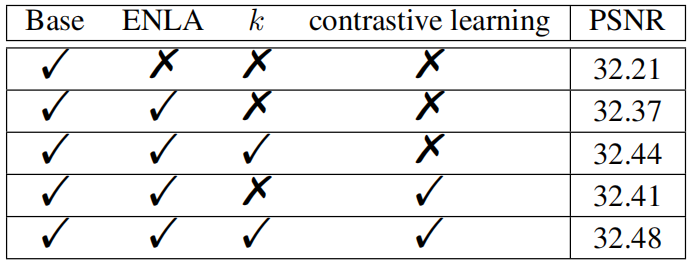
Efficient Non-Local Contrastive Attention 的消融实验如下图所示,
将NLA替换为ENLA提升0.16,引入放大因子k k k
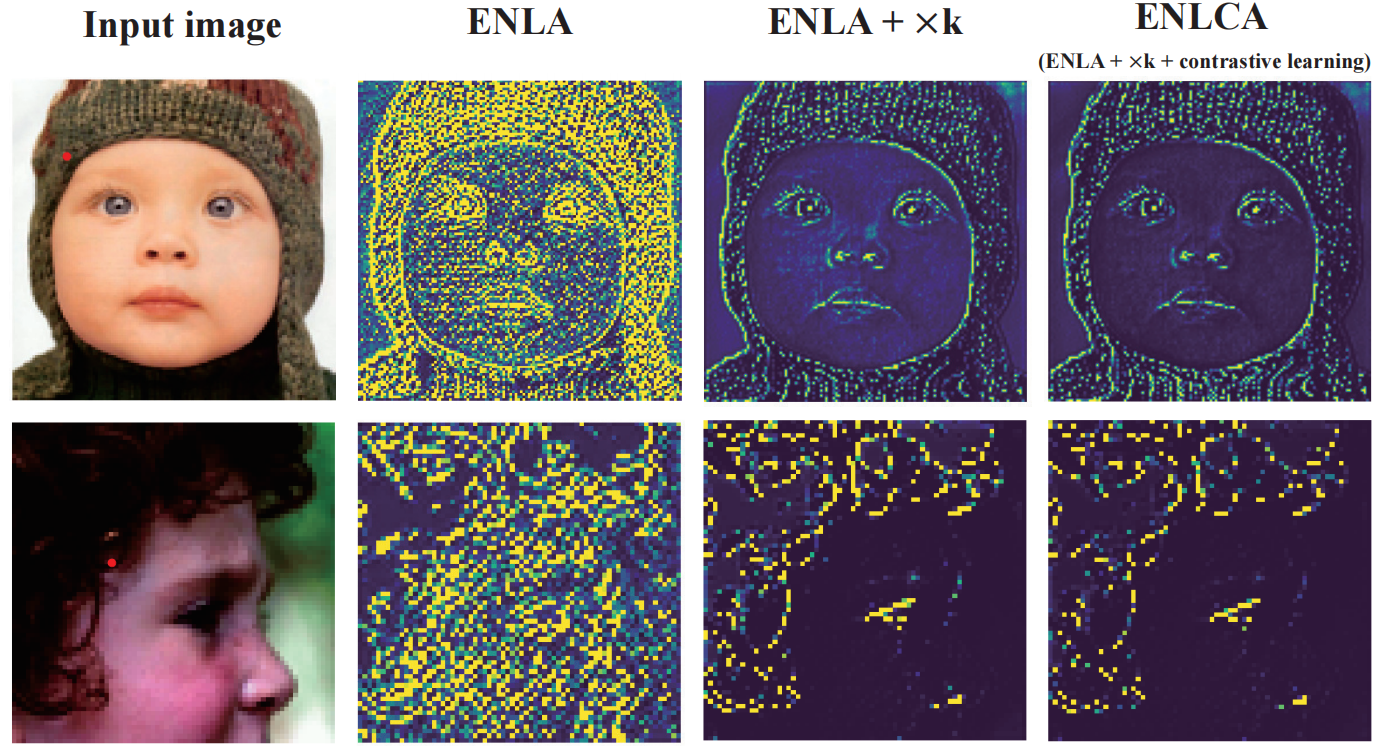
可视化效果如下图所示,
参考文献
[1] Xia B, Hang Y, Tian Y, et al. Efficient Non-Local Contrastive Attention for Image Super-Resolution[J]. arXiv preprint arXiv:2201.03794, 2022.